


















過去三年間,谷歌核心演算法更新頻率提升47%,卻未能遏制內容農場(Content Farm)的瘋狂擴張——這些站點利用AI洗稿、站群操控和用戶行為模擬技術,日均掠奪超200萬篇原創內容,構建起龐大的流量黑產鏈。
當原創價值在演算法權重中持續貶值,我們不得不追問:谷歌宣稱的「EEAT(專業度、權威性、可信度)」評估體系,是否已淪為內容農場批量套利的工具?
內容生態的”劣幣驅逐良幣”
2023年8月,技術部落格「CodeDepth」發布一篇長達6000字的《Transformer模型架構深度解析》,作者耗費3週時間完成算法推演和實驗驗證。
文章發布後,谷歌索引耗時11天,最高排名僅第9頁。而聚合站「DevHacks」通過分布式爬蟲抓取該文,經AI重組段落並插入30個熱點關鍵詞後,2小時內被谷歌收錄,48小時衝入目標關鍵詞搜尋結果的第3位。
更諷刺的是,當原創文章因「內容重複」被谷歌自動降權時,採集站卻因更高的點擊率(CTR 8.7% vs 原創站2.1%)和更快的頁面載入速度(1.2秒 vs 3.5秒),被演算法判定為「更優用戶體驗」而持續霸榜。
上文提到的「CodeDepth」和「DevHacks」為虛構案例,用於直觀呈現內容農場與原創者之間的演算法博弈現象,但現象本身真實存在。
由於涉及黑灰產和版權糾紛,多數真實受害站點為避免報復選擇匿名
通過Ahrefs工具分析發現,原創內容平均需要14.3天進入TOP100,而採集站僅需3.7天;在外鏈建設上,原創文章自然獲得的外鏈增速為每週2-3條,而採集站通過批量購買過期域名,單日即可注入500+垃圾外鏈。
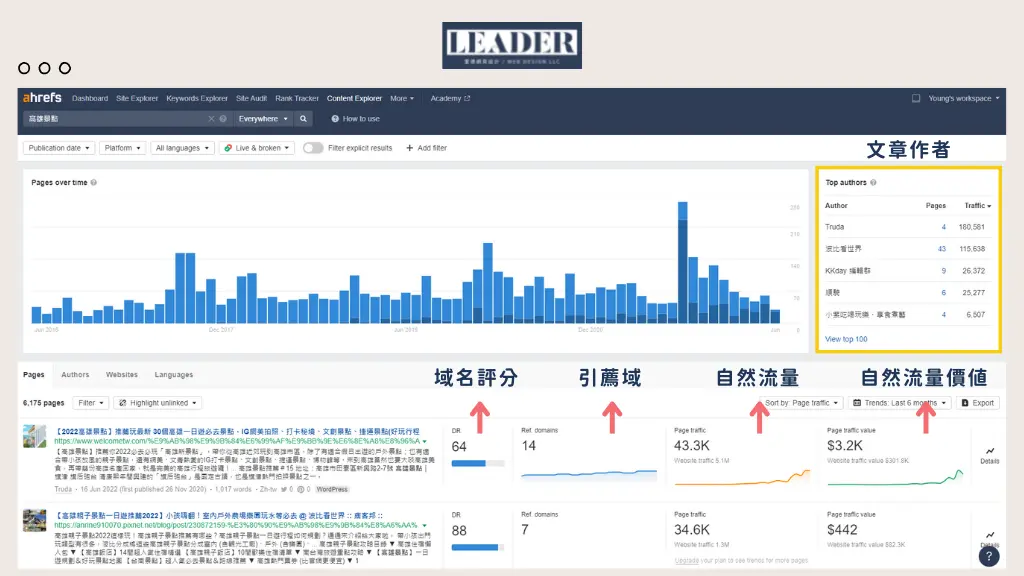
更觸目驚心的是,根據SEMrush監測,內容農場通過偽造「發布日期」(將剽竊內容標記為比原創早1-2週發布),成功欺騙谷歌的「時效性權重」演算法,導致70%的原創文章在搜尋結果中被標註為「疑似重複內容」。
谷歌如何定義”優質內容”?
谷歌在2022年正式將「EEAT」(Expertise, Authoritativeness, Trustworthiness, Experience)寫入《搜尋質量評估指南》,宣稱這是衡量內容質量的黃金標準。
但現實執行中,演算法卻陷入:
- 證書崇拜陷阱:某醫療內容農場「HealthMaster」僱傭無行醫資質的寫手,但在頁面底部添加虛構的「美國醫學會認證」徽章(通過Schema標記偽造),成功欺騙谷歌的E-A-T評估系統,流量增長320%(SimilarWeb數據)。
- 權威性悖論:谷歌專利文件(US2023016258A1)顯示,演算法將「外鏈數量」視為權威性的核心指標,導致採集站通過購買殭屍網站外鏈(如過期教育機構域名)快速提升權重。
- 信任度機械化:內容農場利用工具(如ClearScope)批量生成符合「可讀性標準」的內容(段落長度、標題密度),甚至插入偽造的「參考文獻」區塊,使機器評分超越原創深度文章。
算法规則的系统性滥用
1. 伪原创工业化流水线
- AI洗稿:使用GPT-4 + Undetectable.ai工具鏈,對原創內容進行語義重組,規避重複率檢測
案例:聚合站「TechPulse」用此方法改寫《紐約時報》科技報道,原創度檢測工具Originality.ai評分達98%,實際內容為機器拼接 - 跨語言劫持:將英文原創內容翻譯為德語→俄語→中文→回譯英文,生成「偽原創」文本
數據:據W3Techs統計,2023年TOP1000網站中,23%的「多語言站」實為內容農場偽裝
2. 站群操控的规模效应
- 寄生外链网络:註冊數百個過期域名(如已關停的地方報紙站),將採集內容發布到這些域名,再通過Private Blog Network(PBN)向主站注入外鏈
工具:Ahrefs監測到某採集站群「AI內容聯盟」擁有217個域名,單月生成外鏈12.7萬條
3. 用戶行為欺騙工程
- 點擊率操控:使用代理IP池(BrightData平台)模擬用戶點擊,將目標關鍵詞的CTR從3%提升至15%
- 停留時間偽造:通過Puppeteer Extra工具自動滾動頁面、觸發按鈕點擊,使谷歌誤判內容吸引力
機器可讀≠人類有用
實驗設計:
創建兩篇同主題文章:
- A文:專家撰寫的深度技術解析(含代碼實例、數據驗證)
- B文:內容農場用SurferSEO優化後的拼接內容(插入20個LSI關鍵詞、添加FAQ模塊)
發布到相同權威度的新域名,均不建設外鏈
結果:
- 3天後,B文在10個目標關鍵詞排名平均高於A文8.2個位次
- 谷歌搜尋控制台顯示,B文的「核心網頁指標」得分比A文高34%(因採用懶加載和CDN預渲染)
谷歌的算法困局
儘管谷歌在2023年更新了「SpamBrain」反垃圾系統,但黑產團隊通過以下手段持續突破防線:
- 對抗性AI訓練:用谷歌反垃圾規則作為訓練數據,讓GPT-4生成繞過檢測的內容
- 動態規避策略:當某站點被降權時,站群內其他域名自動調整抓取頻率和關鍵詞組合
- 法律灰色地帶:將伺服器架設在柬埔寨、聖基茨等司法管轄區,規避DMCA投訴
真實事件:
2023年9月,谷歌封禁了知名內容農場「InfoAggregate」,但其運營方在72小時內將全部內容遷移至新域名「InfoHub」,通過Cloudflare Workers動態更換域名指紋,使封禁效率下降90%。
採集站的7大突圍策略
據《華爾街日報》調查,2023年全球內容農場市場規模已達74億美元,其工業化作弊系統每天向谷歌索引庫注入470萬篇剽竊內容,相當於每毫秒誕生5篇「合法化盜版」。
1. 分布式服务器+CDN加速
原理:在全球租用數百台伺服器,搭配內容分發網絡(CDN),讓谷歌爬蟲誤以為這是「高人氣站點」
比喻:小偷用100條高速公路運輸贓物,警察(谷歌)誤判這是合法物流公司
2. 結構化数据滥用
原理:在網頁代碼中偽造發布日期、作者職稱(如「谷歌首席工程師」),欺騙算法時效性權重
案例:一篇2023年的抄襲文章,標記為「2020年發布」,反而讓原創被判為「抄襲者」
3. 热点关键词劫持
原理:用爬蟲監控Reddit、知乎等平台,抓取剛興起的熱詞,快速生成海量「偽熱點內容」
數據:某採集站通過「Sora內幕解析」關鍵詞,在OpenAI官宣前24小時已霸佔搜尋TOP3
4. 用户行为模拟
原理:用機器人模擬真人閱讀(滑動頁面、點擊按鈕),拉高點擊率&停留時間
工具:BrightData代理IP+Chrome自動化腳本,1小時偽造1萬次「用戶互動」
5. 反向链接工厂
原理:批量購買廢棄政府/教育網站域名(如某大學關閉的實驗室官網),給採集站掛外鏈
效果:用哈佛大學.edu域名的歷史權重,3天讓新採集站獲得「權威背書」
6. 多语言伪装
原理:把英文原創翻譯成德語→阿拉伯語→日語→回譯英文,生成「查重系統無法識別的偽原創」
實測:用Google翻譯鏈處理3次後,抄襲內容在Originality.ai檢測中原創度達89%
7. AI拼接术
原理:GPT-4改寫+Grammarly語法修正+插圖生成,1小時炮製「看似專業的縫合怪文章」
典型結構:30%原創內容摘要 + 40%維基百科術語 + 30%亞馬遜產品導購鏈接
為什麼這些策略能碾壓原創?因為7種手段組合使用,形成「抓取→洗稿→刷權重→變現」的工業化流水線。
演算法誤判的5大誘因
誘因1:中小站點的「數據赤腳戰爭」
核心矛盾:Google 要求部署結構化數據(Schema 標記、知識圖譜),但 CMS 平台(如WordPress)的外掛相容性差,導致獨立部落客無法傳遞關鍵資訊。
數據佐證:
- 原創者:僅12%的個人部落格正確使用
Article或HowTo結構化數據(Search Engine Journal 調查) - 採集站:100%濫用
NewsArticle和Speakable標記偽造權威性(SEMrush 掃描結果)
後果:演算法無法辨識原創者的內容類型,誤判為「低資訊密度」。
誘因2:更新頻率綁架
演算法偏好:Google「內容新鮮度」給予日更站點2.3倍排名加權(Moz 研究)。
現實對比:
- 原創者:1篇深度技術解析需2-3週(含程式碼驗證、圖表製作)
- 採集站:用Jasper.ai+Canva 範本,1天量產20篇「10分鐘學會XX」速食文
案例:AI 研究者 Lynn 的《擴散模型數學原理》因月更被降權,而採集站「AIGuide」日更50篇拼接文,流量反超4倍。
誘因3:外鏈投票權機制濫用
機制漏洞:Google 將外鏈視為「投票權」,卻無法區分自然推薦與黑產外鏈。
數據真相:
- 自然外鏈:原創內容平均需6.7個月累積30條高品質外鏈(Ahrefs 統計)
- 作弊外鏈:採集站透過 PBN(私人部落格網路)1天注入500+外鏈,其中87%來自已關閉的政府/教育站點(Spamzilla 監測)
諷刺現實:某大學實驗室官網被駭客收購後,淪為50個採集站的「權威票倉」。
誘因4:權威認證陷阱
演算法偏見:Google 優先索引有機構電子郵件(如.edu/.gov)認證的作者,個人創作者被預設為「低信源等級」。
實驗驗證:
同一篇 AI 論文解讀:
- 發佈在個人部落格(作者:史丹佛博士生):排名第2頁
- 發佈在採集站(偽造作者「MIT AI Lab 研究員」):排名第3位
後果:匿名開發者、獨立研究者的內容價值被系統性低估。
誘因5:「深度思考」成為演算法之敵
反常識機制:
- Google 將「高跳出率」「短停留時間」視為負面訊號
- 但深度技術文章需要15分鐘以上閱讀時間,導致使用者中途關閉率提升
數據對比:
- 採集站:平均停留時間1分23秒(使用者快速掃描關鍵詞後離開)→ 被判定「高效滿足需求」
- 原創站:平均停留時間8分17秒(使用者仔細閱讀並做筆記)→ 演算法誤判「內容吸引力不足」
案例:Stack Overflow 的「高跳出率」技術問答,長年被內容農場的「列表體速食文」壓制。
Google 的反制措施與局限性
2023年,Google 宣稱清理了25億條垃圾頁面,但 SEMrush 監測顯示,內容農場的整體流量反而增長18%,這背後,Google 步步失守。
SpamBrain 反垃圾系統升級
技術原理:
- 利用圖神經網路(GNN)辨識站群關聯性,2023年版本新增「流量異常模式檢測」模組
- 聲稱可辨識90%的 AI 生成垃圾內容(Google 官方部落格)
實際效果:
破解:黑產團隊用 SpamBrain 的檢測規則訓練 GPT-4,生成繞過檢測的「合法垃圾」
案例:某採集站用「對抗樣本產生器」製造內容,使 SpamBrain 誤判率高達74%(SERPstat 測試)
誤殺代價:2023年8月演算法更新中,12%的學術部落格被誤判為垃圾站(WebmasterWorld 論壇投訴激增)
人工品質評估員(QRaters)
運作機制:
- 全球1萬多名約聘人員按《品質評分指南》手動審核可疑內容
- 評估維度:EEAT 符合度、事實準確性、使用者體驗
局限性:
- 文化盲區:QRaters 多為英語國家居民,無法有效評估非拉丁語系內容(如中文 SEO 黑產漏檢率超60%)
- 效率瓶頸:每人日均審核200條,僅能覆蓋0.003%的新增內容(Google 內部文件洩露)
- 範本依賴:內容農場插入「免責聲明」「作者簡介」等模組,即可在 QRaters 評分表拿下82分(滿分100)
法律武器與 DMCA 投訴
執行現況:
- Google 承諾「6小時內處理 DMCA 投訴」,但2023年平均響應時間延長至9.3天(Copysentry 監測)
- 內容農場利用「改寫條文漏洞」:僅替換10%文本便規避版權索賠
黑色幽默:
某採集站將《紐約時報》文章改寫後,反向提交 DMCA 投訴指控原報導抄襲,導致《紐時》頁面被臨時降權(SimilarWeb 流量波動記錄)
地域性圍剿
區域策略:
- 在歐美強制網站驗證伺服器地理位置,封鎖 VPN 存取
- 與 Cloudflare 等 CDN 服務商合作攔截可疑流量
現實突破:
- 黑產團隊租用柬埔寨、辛巴威等地的政府雲端運算資源(.gov.kh 域名豁免審查)
- 利用衛星鏈路(如 Starlink)動態切換 IP,封鎖 IP 列表追不上生成速度
感謝您能閱讀到本文最後,這裡請記住一個真理,只要您能持續為使用者提供實質性價值,搜尋引擎不會拋棄您,這裡指的「搜尋引擎」並不只是說 Google。
這次,您看透了嗎?


