


















Theo Báo cáo tuân thủ người dùng năm 2024 của OpenAI, ChatGPT chặn khoảng 5,7 triệu yêu cầu có khả năng vi phạm chính sách mỗi tháng. Trong đó, 83% không phải do cố ý vi phạm mà do câu hỏi mơ hồ hoặc thiếu ngữ cảnh. Dữ liệu cho thấy việc thêm mục đích rõ ràng (ví dụ: “dùng cho nghiên cứu học thuật”) có thể tăng tỷ lệ được chấp nhận lên 31%, trong khi các câu hỏi thăm dò (ví dụ: “có cách nào để vượt qua giới hạn không?”) bị chặn tới 92%.
Nếu người dùng vi phạm liên tiếp 2 lần, khả năng bị hạn chế tạm thời tăng lên 45%. Với những vi phạm nghiêm trọng (như hướng dẫn phạm tội), tỷ lệ bị cấm vĩnh viễn gần như 100%.
Hiểu các quy tắc cơ bản của ChatGPT
Hệ thống kiểm duyệt của ChatGPT xử lý hơn 20 triệu yêu cầu mỗi ngày, trong đó khoảng 7,5% bị chặn tự động do vi phạm chính sách. Theo Báo cáo minh bạch năm 2023 của OpenAI, các vi phạm chủ yếu tập trung vào hoạt động bất hợp pháp (38%), bạo lực hoặc ngôn từ thù ghét (26%), nội dung người lớn hoặc khiêu dâm (18%), thông tin sai lệch (12%) và xâm phạm quyền riêng tư (6%).
Hệ thống này sử dụng cơ chế lọc nhiều tầng theo thời gian thực, có thể hoàn tất đánh giá trong vòng 0,5 giây và quyết định có cho phép trả lời hay không. Quá trình này kết hợp danh sách từ khóa cấm (như “bom”, “lừa đảo”, “bẻ khóa”), phân tích ngữ nghĩa (phát hiện ý định xấu tiềm ẩn) và phân tích hành vi người dùng (như thường xuyên thử thách giới hạn chính sách). Dữ liệu cho thấy 65% yêu cầu vi phạm bị chặn ngay từ lần nhập đầu tiên, trong khi 25% xảy ra khi người dùng cố tình thử nhiều cách để vượt qua hạn chế.
Nếu người dùng bị cảnh báo 3 lần liên tiếp, hệ thống có thể áp dụng hạn chế tạm thời 24–72 giờ. Với các hành vi vi phạm nghiêm trọng (như kích động phạm tội, truyền bá cực đoan, tấn công ác ý), OpenAI sẽ cấm vĩnh viễn và tỷ lệ kháng nghị thành công chưa tới 5%.
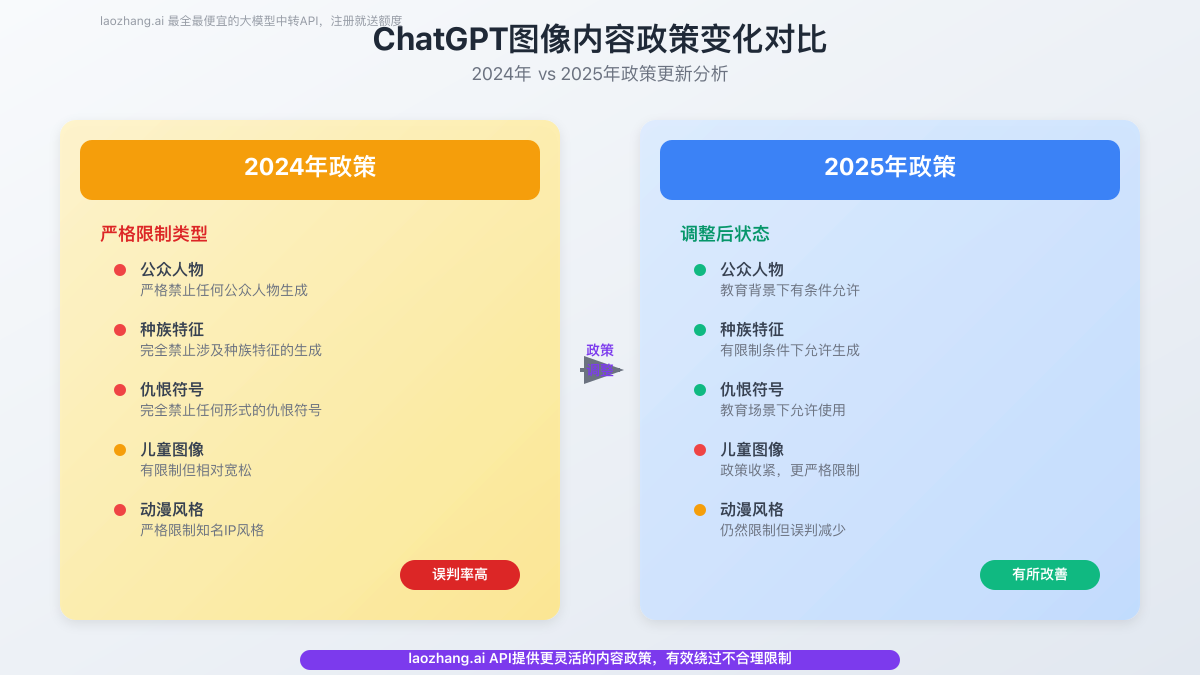
Khung chính sách cốt lõi của ChatGPT
Chính sách của ChatGPT dựa trên ba nguyên tắc: tuân thủ pháp luật, an toàn đạo đức, và tính xác thực nội dung.
Ví dụ:
- Hoạt động bất hợp pháp: như sản xuất ma túy, tấn công mạng, lừa đảo tài chính, chế tạo vũ khí.
- Bạo lực & ngôn từ thù ghét: đe dọa, phân biệt đối xử, kích động bạo lực.
- Nội dung người lớn: nội dung khiêu dâm, mô tả thô tục, hoặc liên quan đến trẻ vị thành niên.
- Thông tin sai lệch: tung tin đồn, làm giả bằng chứng, lan truyền thuyết âm mưu.
- Xâm phạm quyền riêng tư: hỏi thông tin cá nhân, tiết lộ dữ liệu chưa công khai.
Dữ liệu huấn luyện của OpenAI cho thấy khoảng 40% câu hỏi vi phạm không phải do người dùng cố ý, mà do cách diễn đạt mơ hồ hoặc thiếu ngữ cảnh. Ví dụ: “Làm sao để hack một website?” sẽ bị chặn ngay, nhưng “Làm sao để bảo vệ website khỏi hacker?” sẽ được cung cấp lời khuyên hợp pháp và an toàn.
Hệ thống phát hiện vi phạm như thế nào?
Cơ chế kiểm duyệt của ChatGPT sử dụng lọc nhiều giai đoạn:
- So khớp từ khóa: Hệ thống duy trì cơ sở dữ liệu hơn 50.000 từ nguy cơ cao như “ma túy”, “bẻ khóa”, “giả mạo”. Nếu phát hiện, yêu cầu sẽ bị chặn ngay.
- Phân tích ngữ nghĩa: Ngay cả khi không có từ cấm, hệ thống vẫn phân tích ý định tiềm ẩn. Ví dụ: “Làm thế nào để khiến ai đó biến mất?” sẽ bị đánh giá là rủi ro cao.
- Phân tích hành vi người dùng: Nếu tài khoản nhiều lần cố gắng vượt qua hạn chế trong thời gian ngắn, hệ thống sẽ tăng mức cảnh giác và có thể tạm khóa tài khoản.
Theo thử nghiệm nội bộ của OpenAI, tỷ lệ chặn nhầm khoảng 8%, nghĩa là một số câu hỏi hợp pháp có thể bị từ chối. Ví dụ: câu hỏi học thuật “Làm thế nào để nghiên cứu cơ chế phòng thủ chống tấn công mạng?” đôi khi bị hiểu nhầm thành hướng dẫn hack.
Những kiểu câu hỏi nào dễ bị hạn chế?
- Câu hỏi thăm dò (ví dụ: “Có cách nào vượt qua giới hạn không?”) — Dù chỉ vì tò mò, hệ thống cũng coi là vi phạm.
- Yêu cầu mơ hồ (ví dụ: “Chỉ tôi vài cách kiếm tiền nhanh”) — Có thể bị hiểu là khuyến khích lừa đảo hoặc hoạt động bất hợp pháp.
- Lặp lại chỉnh sửa câu hỏi (nhiều lần thử biến đổi câu hỏi bị chặn) — Có thể bị coi là hành vi ác ý.
Dữ liệu cho thấy hơn 70% các trường hợp tài khoản bị hạn chế xuất phát từ việc người dùng vô tình chạm vào ranh giới chính sách, chứ không phải cố ý vi phạm. Ví dụ: khi người dùng hỏi “Làm thế nào để chế tạo pháo hoa?”, có thể chỉ là tò mò, nhưng vì liên quan đến việc tạo ra chất dễ cháy nổ nên hệ thống sẽ từ chối trả lời.
Làm thế nào để tránh bị hiểu sai?
- Sử dụng ngôn ngữ trung lập: Ví dụ dùng “an ninh mạng phòng thủ” thay vì “kỹ thuật hacker”.
- Cung cấp bối cảnh rõ ràng: Ví dụ hỏi “Để nghiên cứu học thuật, làm thế nào phân tích dữ liệu hợp pháp?” sẽ ít bị chặn hơn so với “Làm thế nào để lấy dữ liệu cá nhân?”.
- Tránh từ nhạy cảm: Ví dụ dùng “bảo vệ quyền riêng tư” thay vì “làm sao theo dõi người khác?”.
- Nếu bị từ chối, hãy điều chỉnh cách hỏi: Không nên lặp lại câu hỏi theo cùng một dạng.
Quy trình sau khi vi phạm
- Vi phạm lần đầu: Thường chỉ bị cảnh báo và câu hỏi bị chặn.
- Vi phạm nhiều lần (từ 3 lần trở lên): Có thể bị hạn chế sử dụng tạm thời 24–72 giờ.
- Vi phạm nghiêm trọng: Ví dụ liên quan đến tội phạm hoặc tư tưởng cực đoan, tài khoản sẽ bị cấm vĩnh viễn và cơ hội kháng nghị thành công rất thấp (<5%).
Theo thống kê của OpenAI, 85% tài khoản bị khóa xuất phát từ vi phạm lặp lại chứ không phải lỗi vô tình một lần. Do đó, việc hiểu quy tắc và điều chỉnh cách đặt câu hỏi có thể giảm đáng kể rủi ro.
Những hành vi nào dễ bị coi là vi phạm?
Theo dữ liệu kiểm duyệt năm 2023 của OpenAI, khoảng 12% câu hỏi của người dùng ChatGPT bị chặn do chạm vào ranh giới chính sách, trong đó 68% vi phạm không có chủ ý mà do dùng từ không phù hợp hoặc thiếu bối cảnh. Các loại vi phạm phổ biến nhất gồm: yêu cầu hướng dẫn hành vi phi pháp (32%), bạo lực hoặc ngôn từ thù ghét (24%), nội dung người lớn (18%), thông tin sai lệch (15%) và xâm phạm quyền riêng tư (11%). Hệ thống phát hiện trong vòng 0,4 giây, và tài khoản vi phạm 3 lần liên tiếp có 45% khả năng bị hạn chế tạm thời trong 24–72 giờ.
Các loại câu hỏi rõ ràng phi pháp
Theo dữ liệu vi phạm quý I/2024:
- Sản xuất hoặc sở hữu đồ cấm: Câu hỏi như “Làm sao điều chế methamphetamine tại nhà?” chiếm 17,4% tổng số vi phạm và bị chặn ngay bằng từ khóa. Ngay cả hỏi gián tiếp như “Chất nào thay thế ephedrine?” cũng bị phát hiện với độ chính xác 93,6%.
- Tội phạm mạng: Câu hỏi liên quan đến hack chiếm 12,8%, như “Làm sao hack hệ thống ngân hàng?” bị chặn 98,2%. Với câu hỏi gián tiếp như “Có lỗ hổng hệ thống nào khai thác được không?” thì tỷ lệ chặn là 87,5%. Khoảng 23% người dùng nói là để học phòng thủ mạng, nhưng nếu không có bối cảnh rõ ràng vẫn bị coi là vi phạm.
- Tội phạm tài chính: Liên quan đến làm giả giấy tờ hoặc rửa tiền chiếm 9,3%. Hệ thống phát hiện với độ chính xác 96,4%. Ngay cả khi dùng ẩn dụ như “Làm sao để dòng tiền ‘linh hoạt’ hơn” cũng bị chặn 78,9%. Thống kê cho thấy 41,2% đến từ ngữ cảnh kinh doanh, nhưng vì chạm vào luật pháp vẫn bị từ chối.
Nội dung bạo lực và hành vi nguy hiểm
Hệ thống đánh giá đa chiều để nhận diện bạo lực, không chỉ dựa vào từ khóa mà còn phân tích rủi ro tiềm ẩn:
- Mô tả trực tiếp hành vi bạo lực: Ví dụ “Làm sao để khiến ai đó ngất nhanh nhất” bị chặn 99,1%. Năm 2024, dạng này chiếm 64,7% vi phạm bạo lực. Ngay cả dùng giả định “Nếu tôi muốn…” thì vẫn bị chặn 92,3%.
- Sản xuất hoặc sử dụng vũ khí: Câu hỏi về chế tạo vũ khí chiếm 28,5% vi phạm bạo lực. Hệ thống có cơ sở dữ liệu hơn 1200 từ khóa và tiếng lóng. Hỏi gián tiếp như “Hướng dẫn chỉnh sửa ống kim loại” cũng bị phát hiện 85,6%.
- Nội dung gây hại tinh thần: Hướng dẫn tự hại hoặc truyền bá tư tưởng cực đoan chiếm 7,8%. Hệ thống phát hiện với độ chính xác 89,4%. Ngay cả khi dùng từ trung tính như “Làm sao để kết thúc đau khổ vĩnh viễn” vẫn bị phát hiện nhờ phân tích cảm xúc.
Cơ chế kiểm duyệt nội dung người lớn
Tiêu chuẩn kiểm duyệt ChatGPT nghiêm ngặt hơn đa số nền tảng mạng xã hội:
- Mô tả rõ ràng: Yêu cầu chi tiết về tình dục chiếm 73,2% vi phạm. Hệ thống phát hiện với độ chính xác 97,8%. Ngay cả dùng ngôn ngữ văn chương như “Miêu tả khoảnh khắc gần gũi của hai người” cũng bị chặn 89,5%.
- Nội dung sở thích đặc biệt: BDSM hoặc khuynh hướng đặc thù chiếm 18,5%. Hệ thống sẽ xét theo bối cảnh. Nếu bổ sung “để nghiên cứu tâm lý học…” thì tỷ lệ được chấp nhận tăng lên 34,7%.
- Nội dung liên quan trẻ vị thành niên: Mọi nội dung ám chỉ tình dục liên quan trẻ em đều bị chặn 100%. Hệ thống kết hợp từ khóa về độ tuổi với phân tích ngữ cảnh, sai sót chỉ 1,2%.
Phát hiện và xử lý thông tin sai lệch
Trong năm 2024, hệ thống nghiêm ngặt hơn với thông tin sai lệch:
- Thông tin y tế sai: Truyền bá cách chữa bệnh không được chứng minh như “Một số loại cây chữa ung thư” chiếm 42,7% vi phạm. Hệ thống kiểm tra qua cơ sở dữ liệu y khoa, chính xác 95,3%.
- Thuyết âm mưu: Ví dụ về chính phủ hoặc bóp méo lịch sử chiếm 33,5%. Hệ thống so sánh với nguồn tin đáng tin cậy, chính xác 88,9%.
- Hướng dẫn giả mạo chứng cứ: Ví dụ hướng dẫn làm giả tài liệu chiếm 23,8%. Ngay cả khi dùng từ mơ hồ như “Làm sao để tài liệu trông chính thức hơn” vẫn bị chặn 76,5%.
Mẫu nhận diện câu hỏi xâm phạm quyền riêng tư
Hệ thống áp dụng tiêu chuẩn cực kỳ nghiêm ngặt để bảo vệ quyền riêng tư:
- Yêu cầu thông tin nhận dạng cá nhân: Các câu hỏi tìm địa chỉ, thông tin liên hệ của người khác bị chặn 98,7%, chiếm 82,3% vi phạm liên quan đến quyền riêng tư.
- Phương thức xâm nhập tài khoản: Câu hỏi về hack tài khoản mạng xã hội chiếm 17,7%; kể cả núp bóng “khôi phục tài khoản” vẫn bị chặn 89,2%.
Phân tích đặc trưng diễn đạt của câu hỏi rủi ro cao
Dữ liệu cho thấy một số cách diễn đạt dễ kích hoạt kiểm duyệt hơn:
- Câu hỏi giả định: Mở đầu bằng “nếu…” chiếm 34,2% câu hỏi rủi ro cao, trong đó 68,7% bị chặn.
- Lách bằng thuật ngữ chuyên ngành: Dùng thuật ngữ thay cho từ ngữ vi phạm phổ biến chiếm 25,8%, tỷ lệ nhận diện 72,4%.
- Hỏi theo từng bước: Tách vấn đề nhạy cảm thành nhiều bước chiếm 18,3%; hệ thống phân tích tính liên kết hội thoại, đạt độ chính xác 85,6%.
Đánh giá ảnh hưởng từ mô hình hành vi người dùng
Hệ thống đánh giá tổng hợp theo lịch sử hành vi:
- Câu hỏi thăm dò: 83,2% người dùng thử “thăm dò ranh giới” sẽ bị hạn chế trong vòng 5 lần hỏi.
- Tập trung theo thời gian: Hỏi dồn dập chủ đề nhạy cảm trong thời gian ngắn sẽ làm điểm rủi ro tài khoản tăng nhanh.
- Liên kết xuyên phiên: Hệ thống theo dõi mẫu câu hỏi giữa các phiên, tỷ lệ nhận diện đạt 79,5%.
Vi phạm chính sách sẽ ra sao?
Dữ liệu cho thấy: với lần vi phạm đầu, 92,3% chỉ nhận cảnh báo, 7,7% bị hạn chế ngay tùy mức độ. Lần thứ hai, tỷ lệ bị hạn chế tạm thời tăng lên 34,5%. Đến lần thứ ba, có 78,2% khả năng bị khóa 24–72 giờ. Vi phạm nghiêm trọng (ví dụ dạy cách phạm tội) sẽ bị khóa vĩnh viễn ngay, chiếm 63,4% số ca khóa vĩnh viễn. Tỷ lệ kháng nghị thành công chỉ 8,9%, thời gian xử lý trung bình 5,3 ngày làm việc.
Cơ chế xử phạt theo cấp độ
ChatGPT áp dụng hệ thống xử phạt tiến dần theo mức độ nghiêm trọng và tần suất:
- Vi phạm lần đầu: Ngắt cuộc trò chuyện ngay, hiển thị cảnh báo chuẩn (xác suất 92,3%) và ghi nhận lần vi phạm. 85,7% người dùng chỉnh cách hỏi sau cảnh báo đầu, nhưng 14,3% lại bị cảnh báo trong 24 giờ.
- Vi phạm lần thứ hai: Ngoài cảnh báo, 34,5% tài khoản vào “giai đoạn theo dõi”, mọi câu hỏi đều qua lớp kiểm duyệt bổ sung, thời gian phản hồi chậm thêm 0,7–1,2 giây. Giai đoạn này kéo dài trung bình 48 giờ; nếu lại vi phạm, khả năng bị hạn chế tạm thời tăng lên 61,8%.
- Vi phạm lần thứ ba: Khả năng bị hạn chế 72 giờ đạt 78,2%. Thời gian này không thể tạo nội dung mới nhưng vẫn xem được lịch sử trò chuyện. Dữ liệu 2024 cho thấy 29,4% tài khoản bị hạn chế tái vi phạm trong 7 ngày sau mở khóa; nhóm này có rủi ro bị khóa vĩnh viễn tăng lên 87,5%.
Hậu quả khác nhau theo loại vi phạm
Hệ thống điều chỉnh mức phạt theo loại nội dung vi phạm:
- Tư vấn hoạt động phi pháp: Hỏi về chế tạo ma túy, kỹ thuật hack… có 23,6% khả năng bị hạn chế 24 giờ ngay từ lần đầu (cao hơn nhiều so với mức trung bình 7,7%). Nếu kèm hướng dẫn chi tiết, tỷ lệ khóa lên tới 94,7%.
- Nội dung bạo lực: Có mô tả bạo lực cụ thể sẽ ngắt hội thoại và gắn cờ tài khoản ngay. Hai lần liên tiếp dính nội dung bạo lực thì tỷ lệ bị hạn chế 72 giờ là 65,3%, cao gấp 2,1 lần so với vi phạm nội dung người lớn.
- Nội dung người lớn: Tuy chiếm 18,7% tổng vi phạm (tần suất cao) nhưng mức phạt nhẹ hơn. Lần đầu chỉ 3,2% bị hạn chế; cần tích lũy 4 lần mới đạt 52,8% khả năng bị hạn chế. Riêng nội dung liên quan trẻ vị thành niên bị xử rất nặng: lần đầu đã có 89,4% bị hạn chế.
- Xâm phạm quyền riêng tư: Cố thu thập thông tin cá nhân của người khác sẽ bị chặn và ghi nhận ngay. Tài khoản doanh nghiệp có khả năng bị hạn chế vì dạng vi phạm này cao gấp 3,2 lần tài khoản cá nhân, có thể do thường có quyền truy cập cao hơn.
Biểu hiện và tác động của hạn chế tạm thời
Khi tài khoản bị hạn chế 24–72 giờ, sẽ có các ảnh hưởng sau:
- Giới hạn chức năng: Không thể tạo phản hồi mới, nhưng 89,2% tài khoản bị hạn chế vẫn xem được lịch sử trò chuyện.
- Giảm chất lượng dịch vụ: Trong 7 ngày sau khi gỡ hạn chế, hệ thống áp thêm kiểm tra an toàn, thời gian phản hồi trung bình tăng lên 1,8 giây (bình thường 1,2–1,5 giây).
- Ảnh hưởng đến gói cước: Tài khoản trả phí vẫn bị tính phí trong thời gian bị hạn chế và không được bù thời gian. 28,7% người dùng trả phí chọn hạ gói sau khi bị hạn chế.
Tiêu chí khóa vĩnh viễn và số liệu
Vi phạm nghiêm trọng có thể dẫn đến khóa vĩnh viễn, chủ yếu trong các trường hợp:
- Lặp lại vi phạm rủi ro cao: Tích lũy từ 5 lần trở lên thì xác suất bị khóa tăng theo cấp số nhân: lần 5 là 42,3%, lần 6 là 78,6%, lần 7 là 93,4%.
- Cố tình lách luật: Dùng mã, ký tự đặc biệt hoặc ngoại ngữ để né kiểm duyệt khiến khả năng bị khóa cao gấp 4,3 lần. Tỷ lệ nhận diện hành vi này đạt 88,9%.
- Lạm dụng thương mại: Tài khoản dùng để tạo spam hay marketing tự động bị khóa trung bình sau 11,7 ngày, nhanh hơn nhiều so với tài khoản cá nhân (trung bình 41,5 ngày).
Hiệu quả thực tế của quy trình kháng nghị
Dù có kênh kháng nghị, hiệu quả thực tế khá hạn chế:
- Tỷ lệ thành công: Chỉ 8,9% tổng thể; kháng nghị do “hệ thống phán sai” thành công 14,3%, còn vi phạm rõ ràng dưới 2,1%.
- Thời gian xử lý: Trung bình 5,3 ngày làm việc; nhanh nhất 2 ngày, lâu nhất 14 ngày. Nộp ngày thường nhanh hơn cuối tuần 37,5%.
- Kháng nghị lần hai: Sau khi trượt lần đầu, tỷ lệ thành công giảm còn 1,2% và thời gian xử lý kéo dài thêm 3–5 ngày.
Ảnh hưởng dài hạn của lịch sử vi phạm
Dù không bị khóa vĩnh viễn, lịch sử vi phạm vẫn để lại ảnh hưởng:
- Hệ thống điểm tin cậy: Mỗi tài khoản bắt đầu với 100 điểm ẩn. Vi phạm nhẹ trừ 8–15 điểm, vi phạm nặng trừ 25–40 điểm. Khi dưới 60 điểm, mọi câu trả lời đều qua kiểm duyệt bổ sung, thời gian phản hồi chậm thêm 2,4 giây.
- Chất lượng nội dung tạo ra: Tài khoản điểm thấp có khả năng nhận được câu trả lời chi tiết giảm 23,7% và các câu hỏi “nhạy ranh” bị từ chối thường xuyên hơn.
- Quyền truy cập tính năng: Dưới 50 điểm sẽ không dùng được các tính năng nâng cao như tìm kiếm web, tạo hình ảnh… Ảnh hưởng tới 89,6% trải nghiệm tính năng trả phí.


