


















OpenAI 2024 उपयोगकर्ता अनुपालन रिपोर्ट के अनुसार, ChatGPT प्रति माह लगभग 57 लाख संभावित उल्लंघनकारी प्रश्नों को रोकता है, जिनमें से 83% मामलों का कारण जानबूझकर उल्लंघन नहीं बल्कि अस्पष्ट अभिव्यक्ति या संदर्भ की कमी होता है। आंकड़े दिखाते हैं कि यदि उपयोगकर्ता अपने प्रश्न का उद्देश्य स्पष्ट रूप से बताते हैं (जैसे “शैक्षणिक शोध के लिए”), तो स्वीकृति दर में 31% की वृद्धि होती है, जबकि परीक्षणात्मक प्रश्न (जैसे “क्या कोई तरीका है प्रतिबंधों को बाईपास करने का?”) की ब्लॉक दर 92% तक पहुँच जाती है।
यदि उपयोगकर्ता लगातार 2 बार उल्लंघन करते हैं, तो अस्थायी प्रतिबंध की संभावना 45% तक बढ़ जाती है। जबकि गंभीर उल्लंघनों (जैसे अपराध संबंधित निर्देश) के मामलों में लगभग 100% स्थायी प्रतिबंध लगाया जाता है।
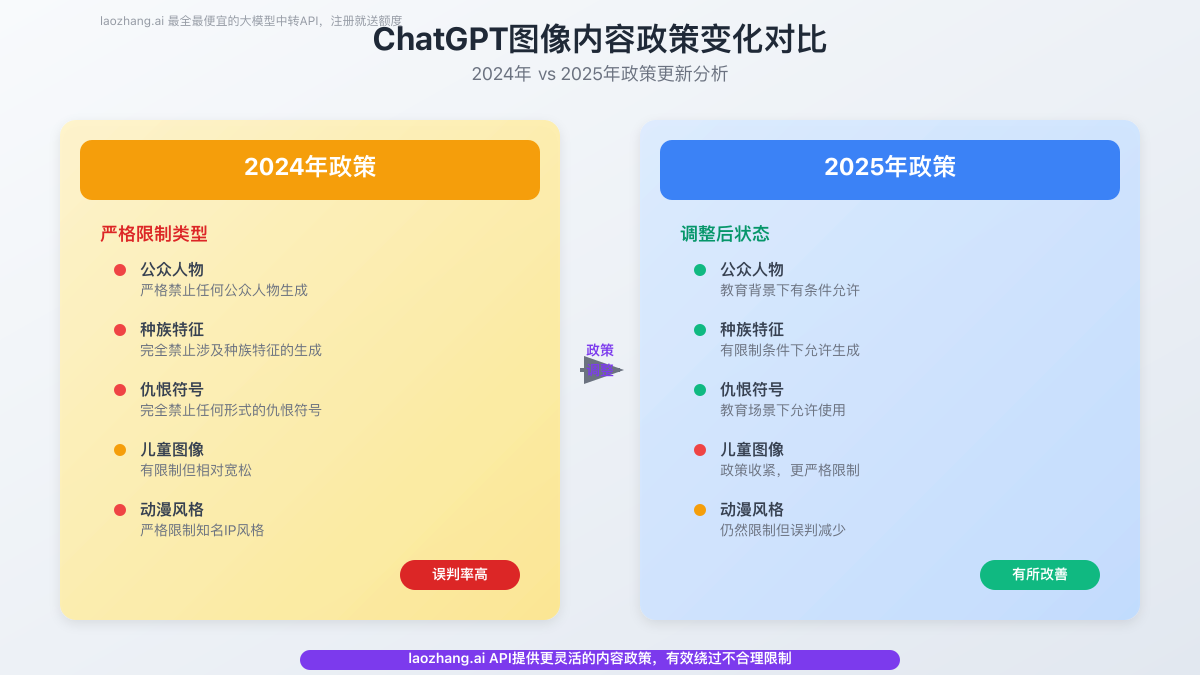
ChatGPT के बुनियादी नियमों को समझें
ChatGPT की नीति समीक्षा प्रणाली प्रतिदिन 2 करोड़ से अधिक उपयोगकर्ता अनुरोधों को संसाधित करती है, जिनमें से लगभग 7.5% प्रश्न स्वचालित रूप से नीति उल्लंघन के कारण अवरुद्ध हो जाते हैं। OpenAI 2023 की पारदर्शिता रिपोर्ट के अनुसार, उल्लंघन मुख्य रूप से इन क्षेत्रों में केंद्रित हैं: अवैध गतिविधियाँ (38%), हिंसा या घृणास्पद भाषण (26%), वयस्क या अश्लील सामग्री (18%), भ्रामक जानकारी (12%), और गोपनीयता का उल्लंघन (6%)।
यह प्रणाली रीयल-टाइम मल्टी-लेयर फ़िल्टरिंग तंत्र का उपयोग करती है, जो 0.5 सेकंड में समीक्षा पूरी कर लेती है और तय करती है कि उत्तर देना है या नहीं। समीक्षा प्रक्रिया में कीवर्ड ब्लैकलिस्ट (जैसे “बम”, “धोखाधड़ी”, “हैक”), सार्थक विश्लेषण (छिपे हुए हानिकारक इरादों की पहचान), और उपयोगकर्ता व्यवहार पैटर्न (जैसे बार-बार नीतियों की सीमा की जाँच करना) शामिल हैं। आँकड़े दिखाते हैं कि 65% उल्लंघनकारी प्रश्न पहली बार में ही रोक दिए जाते हैं, जबकि 25% उल्लंघन उपयोगकर्ता द्वारा बार-बार प्रयास करने पर होते हैं।
यदि उपयोगकर्ता लगातार 3 बार नीति चेतावनी को ट्रिगर करते हैं, तो सिस्टम 24 से 72 घंटे का अस्थायी प्रतिबंध लगा सकता है। वहीं गंभीर उल्लंघनों (जैसे अपराध के लिए उकसाना, उग्रवाद फैलाना, या किसी पर दुर्भावनापूर्ण हमला करना) पर OpenAI सीधे स्थायी प्रतिबंध लागू करता है, और अपील की सफलता दर 5% से कम होती है।
ChatGPT की मुख्य नीति रूपरेखा
ChatGPT की नीतियाँ तीन सिद्धांतों पर आधारित हैं: कानूनी अनुपालन, नैतिक सुरक्षा और सामग्री की प्रामाणिकता।
उदाहरण के लिए:
- अवैध गतिविधियाँ: जैसे ड्रग्स का निर्माण, हैकिंग, वित्तीय धोखाधड़ी, हथियार बनाना।
- हिंसा और घृणास्पद भाषण: धमकी, भेदभाव, हिंसा के लिए उकसाना।
- वयस्क सामग्री: अश्लीलता, स्पष्ट विवरण, या नाबालिगों से संबंधित कोई भी सामग्री।
- भ्रामक जानकारी: अफवाहें गढ़ना, सबूत गढ़ना, षड्यंत्र सिद्धांत फैलाना।
- गोपनीयता का उल्लंघन: दूसरों की व्यक्तिगत जानकारी माँगना या गैर-सार्वजनिक डेटा लीक करना।
OpenAI के प्रशिक्षण डेटा से पता चलता है कि लगभग 40% उल्लंघनकारी प्रश्न जानबूझकर नहीं किए गए होते, बल्कि अस्पष्ट भाषा या संदर्भ की कमी के कारण होते हैं। उदाहरण के लिए, यदि कोई पूछे “वेबसाइट को कैसे हैक करें?”, तो उसे तुरंत अस्वीकार कर दिया जाएगा, लेकिन यदि प्रश्न हो “वेबसाइट को हैकिंग से कैसे बचाएँ?”, तो सिस्टम उचित सुरक्षा सलाह देगा।
सिस्टम उल्लंघनकारी सामग्री का पता कैसे लगाता है?
ChatGPT की समीक्षा प्रणाली बहु-चरणीय फ़िल्टरिंग अपनाती है:
- कीवर्ड मिलान: सिस्टम में 50,000 से अधिक उच्च-जोखिम वाले शब्द का डेटाबेस है, जैसे “ड्रग्स”, “हैक”, “फर्जीवाड़ा”। यदि ये शब्द मिलते हैं, तो प्रश्न तुरंत ब्लॉक कर दिया जाता है।
- सार्थक विश्लेषण: भले ही स्पष्ट शब्द न हों, सिस्टम इरादे का विश्लेषण करता है। उदाहरण: “किसी को गायब कैसे करें?” को उच्च-जोखिम के रूप में पहचाना जाएगा।
- उपयोगकर्ता व्यवहार विश्लेषण: यदि कोई खाता कम समय में बार-बार प्रतिबंधों को पार करने की कोशिश करता है, तो सिस्टम जोखिम स्तर बढ़ाता है और अस्थायी ब्लॉक भी कर सकता है।
OpenAI के आंतरिक परीक्षणों के अनुसार, गलत ब्लॉक दर लगभग 8% है, यानी कुछ वैध प्रश्न भी गलती से ब्लॉक हो सकते हैं। उदाहरण के लिए, शैक्षणिक चर्चा “साइबर हमलों से बचाव के तंत्र का अध्ययन कैसे करें?” को कभी-कभी गलती से हैकिंग ट्यूटोरियल समझ लिया जाता है।
कौन से प्रश्न आसानी से प्रतिबंध को ट्रिगर कर सकते हैं?
- परीक्षणात्मक प्रश्न (जैसे: “क्या कोई तरीका है प्रतिबंधों को बाईपास करने का?”) — भले ही जिज्ञासा से पूछे गए हों, इन्हें उल्लंघन का प्रयास माना जाएगा।
- अस्पष्ट अनुरोध (जैसे: “मुझे जल्दी पैसा कमाने के शॉर्टकट सिखाओ”) — इन्हें धोखाधड़ी या अवैध गतिविधियों के प्रोत्साहन के रूप में समझा जा सकता है।
- बार-बार संशोधित प्रश्न (जैसे बार-बार निषिद्ध जानकारी पाने की कोशिश करना) — इन्हें दुर्भावनापूर्ण व्यवहार माना जा सकता है।
डेटा से पता चलता है कि 70% से अधिक खाता प्रतिबंध मामलों का कारण उपयोगकर्ताओं द्वारा अनजाने में नीति की सीमाओं को छूना होता है, न कि जानबूझकर उल्लंघन करना।
उदाहरण के लिए, यदि कोई उपयोगकर्ता पूछता है “पटाखे कैसे बनाए जाते हैं?”, तो यह केवल जिज्ञासा हो सकती है, लेकिन क्योंकि इसमें ज्वलनशील पदार्थ शामिल होते हैं, सिस्टम फिर भी जवाब देने से मना कर देगा।
गलतफहमी से कैसे बचें?
- तटस्थ भाषा का प्रयोग करें: उदाहरण के लिए, “हैकिंग तकनीक” के बजाय “साइबर सुरक्षा रक्षा” कहें।
- स्पष्ट संदर्भ प्रदान करें: “शैक्षणिक अनुसंधान के लिए, कानूनी रूप से डेटा का विश्लेषण कैसे करें?” कहना “निजी डेटा कैसे प्राप्त करें?” की तुलना में अवरुद्ध होने की संभावना कम करता है।
- संवेदनशील शब्दों से बचें: उदाहरण के लिए, “किसी की जानकारी पर जासूसी कैसे करें?” के बजाय “गोपनीयता संरक्षण” कहें।
- यदि अस्वीकार किया जाए, तो प्रश्न को दोबारा लिखें: बार-बार एक ही प्रश्न पूछने के बजाय।
उल्लंघन के बाद क्या होता है?
- पहला उल्लंघन: आमतौर पर केवल एक चेतावनी मिलती है और प्रश्न अवरुद्ध हो जाता है।
- कई उल्लंघन (3+ बार): इससे 24–72 घंटे की अस्थायी रोक लग सकती है।
- गंभीर उल्लंघन: आपराधिक मार्गदर्शन, उग्रवाद आदि शामिल होने पर → खाते को स्थायी रूप से प्रतिबंधित कर दिया जाता है, और अपील की सफलता दर बहुत कम (<5%) होती है।
OpenAI आँकड़ों के अनुसार, 85% प्रतिबंधित खाते बार-बार उल्लंघनों के कारण थे, न कि एक बार की गलती के कारण। इसलिए, नियमों को समझना और प्रश्न पूछने का तरीका समायोजित करना खाता जोखिमों को काफी कम कर सकता है।
कौन से व्यवहार उल्लंघन के रूप में चिह्नित होने की संभावना रखते हैं?
OpenAI के 2023 मॉडरेशन डेटा के आधार पर, लगभग 12% ChatGPT उपयोगकर्ता प्रश्न नीति की लाल रेखाओं को छूने के कारण अवरुद्ध हो गए, और 68% उल्लंघन जानबूझकर नहीं थे, बल्कि खराब वाक्य संरचना या संदर्भ की कमी से हुए।
सबसे आम उल्लंघन प्रकार हैं: अवैध गतिविधि (32%), हिंसक या घृणास्पद सामग्री (24%), वयस्क सामग्री (18%), गलत जानकारी (15%) और गोपनीयता उल्लंघन (11%)।
सिस्टम सामग्री मॉडरेशन को 0.4 सेकंड में पूरा कर सकता है, और जिन खातों में लगातार 3 उल्लंघन होते हैं, उनमें 45% संभावना होती है कि वे 24–72 घंटों के लिए अस्थायी रूप से प्रतिबंधित हो जाएंगे।
स्पष्ट रूप से अवैध प्रश्न प्रकार
Q1 2024 उल्लंघन डेटा का विश्लेषण:
- अवैध वस्तुओं का निर्माण और पहुँच: दवाओं के निर्माण के बारे में पूछना (जैसे “घर पर मेथ कैसे बनाएं?”) सभी उल्लंघनों का 17.4% था। ये तुरंत कीवर्ड फ़िल्टर से पकड़े जाते हैं। अधिक सूक्ष्म रूप जैसे “कौन से रसायन एपhedrine को बदल सकते हैं?” भी 93.6% सटीकता के साथ पकड़े जाते हैं।
- साइबर अपराध: 12.8% उल्लंघन। प्रत्यक्ष प्रश्न जैसे “बैंक सिस्टम को कैसे हैक करें?” 98.2% समय अवरुद्ध होते हैं, जबकि अधिक सूक्ष्म प्रश्न (“कौन सी कमजोरियों का फायदा उठाया जा सकता है?”) 87.5% समय अवरुद्ध होते हैं। दिलचस्प बात यह है कि लगभग 23% उपयोगकर्ताओं ने कहा कि वे केवल साइबर सुरक्षा रक्षा सीखना चाहते थे, लेकिन बिना संदर्भ के, सिस्टम ने फिर भी अवरुद्ध कर दिया।
- वित्तीय अपराध: दस्तावेज़ों की जालसाजी, मनी लॉन्ड्रिंग आदि से संबंधित प्रश्न 9.3% थे। सिस्टम इन्हें 96.4% समय पकड़ता है, भले ही वे छिपे हों (“पैसे के प्रवाह को अधिक ‘लचीला’ कैसे बनाएं?”) में 78.9% अवरोध दर होती है। डेटा से पता चलता है कि इनमें से 41.2% व्यापार संबंधी क्वेरी से आए थे, लेकिन क्योंकि वे कानूनी रेखाओं को पार करते हैं, वे फिर भी अवरुद्ध हो जाते हैं।
हिंसा और खतरनाक व्यवहार
सिस्टम हिंसा का पता लगाने के लिए बहु-स्तरीय मॉडल का उपयोग करता है, केवल शब्दों से परे जाकर संभावित हानि का आकलन करता है:
- स्पष्ट हिंसक कृत्य: सीधे पूछना कि किसी को कैसे चोट पहुँचाई जाए (“किसी को बेहोश करने का सबसे तेज़ तरीका”) 99.1% समय अवरुद्ध होता है। 2024 में, यह सभी हिंसक उल्लंघनों का 64.7% था। यहां तक कि काल्पनिक रूप (“क्या होगा अगर मैं चाहता…”) में भी अवरोध दर 92.3% थी।
- हथियार निर्माण और उपयोग: 28.5% उल्लंघन। सिस्टम के पास 1200+ हथियार शब्दों और स्लैंग का डेटाबेस है। यहां तक कि छिपे हुए प्रश्न जैसे “मेटल पाइप मॉडिफिकेशन गाइड” भी 85.6% समय पकड़े जाते हैं।
- मनोवैज्ञानिक नुकसान: आत्म-हानि या उग्रवादी विचारों को बढ़ावा देना 7.8% था। पहचान दर 89.4% है। ये अक्सर तटस्थ लगते हैं (“दर्द को स्थायी रूप से कैसे समाप्त करें”), लेकिन भावनात्मक विश्लेषण फिर भी इन्हें चिह्नित करता है।
वयस्क सामग्री का पता लगाना
वयस्क सामग्री के लिए ChatGPT के मानक अधिकांश प्लेटफ़ॉर्म की तुलना में कड़े हैं:
- स्पष्ट विवरण: प्रत्यक्ष यौन सामग्री अनुरोध सभी वयस्क उल्लंघनों का 73.2% थे। एक स्तरीय कीवर्ड सिस्टम इन्हें 97.8% सटीकता से पकड़ता है। यहां तक कि साहित्यिक अभिव्यक्ति जैसे “एक अंतरंग क्षण का वर्णन करें” 89.5% समय अवरुद्ध होती है।
- किंक और फेटिश: BDSM या फेटिश सामग्री जैसे विषय 18.5% थे। सिस्टम संदर्भ को ध्यान में रखता है। डेटा से पता चला कि एक शैक्षणिक अस्वीकरण जोड़ने (“मनोविज्ञान अनुसंधान के लिए…”) से अनुमोदन दर 34.7% तक बढ़ गई।
- नाबालिगों से संबंधित सामग्री: नाबालिगों से संबंधित कोई भी यौन सामग्री 100% समय अवरुद्ध होती है। सिस्टम उम्र-संबंधी कीवर्ड + संदर्भ विश्लेषण का उपयोग करता है, जिसमें केवल 1.2% गलत सकारात्मक दर होती है।
गलत जानकारी का पता लगाना
2024 में, सिस्टम ने गलत जानकारी से निपटने को और मजबूत किया:
- चिकित्सा संबंधी गलत जानकारी: अप्रमाणित उपचार (“यह पौधा कैंसर ठीक करता है”) सभी गलत जानकारी उल्लंघनों का 42.7% था। एक चिकित्सा ज्ञान ग्राफ इन्हें 95.3% सटीकता से जांचता है।
- षड्यंत्र सिद्धांत: सरकार की साजिशें, संशोधित इतिहास आदि 33.5% थे। सिस्टम विश्वसनीय स्रोतों की तुलना करता है, और 88.9% सटीकता से पकड़ता है।
- नकली साक्ष्य मार्गदर्शन: दस्तावेज़ों की नकली बनाने की शिक्षा 23.8% थी। यहां तक कि अस्पष्ट रूप (“दस्तावेज़ों को अधिक आधिकारिक कैसे दिखाएं”) 76.5% समय अवरुद्ध होते हैं।
गोपनीयता-उल्लंघन प्रश्नों का पता लगाने के पैटर्न
सिस्टम गोपनीयता सुरक्षा के लिए अत्यंत कड़े मानक लागू करता है:
- व्यक्तिगत पहचान संबंधी जानकारी के अनुरोध: किसी का पता, संपर्क विवरण आदि पूछने वाले प्रश्न 98.7% मामलों में ब्लॉक हो जाते हैं और ये सभी गोपनीयता-संबंधी उल्लंघनों का 82.3% हिस्सा बनाते हैं।
- खाता हैकिंग विधियाँ: सोशल अकाउंट्स को तोड़ने से संबंधित प्रश्न 17.7% बनाते हैं। भले ही इन्हें “खाता पुनर्प्राप्ति” के बहाने पूछा जाए, इन्हें 89.2% मामलों में ब्लॉक कर दिया जाता है।
उच्च-जोखिम वाले प्रश्नों की अभिव्यक्ति के पैटर्न
डेटा दर्शाता है कि कुछ प्रकार की भाषा अधिकतर सामग्री मॉडरेशन को ट्रिगर करती है:
- काल्पनिक प्रश्न: “अगर ऐसा हो तो…” से शुरू होने वाले प्रश्न उच्च-जोखिम प्रश्नों का 34.2% होते हैं, जिनमें से 68.7% ब्लॉक हो जाते हैं।
- फ़िल्टर से बचने के लिए तकनीकी शब्दों का उपयोग: प्रतिबंधित शब्दों को उद्योग संबंधी शब्दों से बदलना 25.8% बनाता है, जिसकी पहचान दर 72.4% है।
- कदम-दर-कदम पूछना: संवेदनशील प्रश्न को कई छोटे हिस्सों में बांटना 18.3% बनाता है। सिस्टम बातचीत के प्रवाह का विश्लेषण करके इन्हें पकड़ता है, जिसकी शुद्धता 85.6% है।
उपयोगकर्ता व्यवहार पैटर्न का प्रभाव
सिस्टम उपयोगकर्ता के पिछले व्यवहार का भी मूल्यांकन करता है:
- सीमाओं का परीक्षण: 83.2% उपयोगकर्ता जो बार-बार नीति की सीमाओं को परखते हैं, 5 प्रयासों के भीतर प्रतिबंधित हो जाते हैं।
- समय पर एकाग्रता: कम समय में बहुत से संवेदनशील प्रश्न पूछने से खाते का जोखिम स्कोर तेजी से बढ़ जाता है।
- सत्रों के पार ट्रैकिंग: सिस्टम अलग-अलग सत्रों में प्रश्न पैटर्न को 79.5% शुद्धता के साथ ट्रैक करता है।
अगर आप नियम तोड़ते हैं तो क्या होगा?
डेटा से पता चलता है कि पहली बार उल्लंघन पर 92.3% उपयोगकर्ताओं को सिर्फ चेतावनी मिलती है, जबकि 7.7% को गंभीरता के आधार पर तुरंत प्रतिबंधित कर दिया जाता है। दूसरी बार पर अस्थायी प्रतिबंध 34.5% तक बढ़ जाता है। तीसरी बार 24–72 घंटे तक लॉक होने की 78.2% संभावना होती है। गंभीर उल्लंघन (जैसे अपराध के तरीकों को सिखाना) तुरंत प्रतिबंध का कारण बनते हैं—63.4% स्थायी प्रतिबंध इन्हीं से आते हैं। अपील केवल 8.9% मामलों में सफल होती है और औसत समीक्षा समय 5.3 कार्य दिवस है।
चरण-दर-चरण दंड प्रणाली
ChatGPT गंभीरता और आवृत्ति के आधार पर प्रगतिशील दंड प्रणाली लागू करता है:
- पहला उल्लंघन: चैट तुरंत बंद हो जाती है, एक मानक चेतावनी दिखाई देती है (92.3%) और मामला दर्ज हो जाता है। 85.7% उपयोगकर्ता इसके बाद अपना व्यवहार बदलते हैं, लेकिन 14.3% 24 घंटों में फिर उल्लंघन करते हैं।
- दूसरा उल्लंघन: चेतावनी के अलावा, 34.5% खातों को “अवलोकन अवधि” में डाल दिया जाता है, जहाँ सभी प्रश्न अतिरिक्त समीक्षा से गुजरते हैं। प्रतिक्रिया समय 0.7–1.2 सेकंड धीमा हो जाता है। यह अवधि लगभग 48 घंटे चलती है, और फिर से उल्लंघन होने पर अस्थायी प्रतिबंध की संभावना 61.8% तक बढ़ जाती है।
- तीसरा उल्लंघन: 72 घंटे तक प्रतिबंधित होने की 78.2% संभावना होती है। इस दौरान, उपयोगकर्ता पुरानी चैट देख सकता है लेकिन नई उत्पन्न नहीं कर सकता। 2024 में, 29.4% प्रतिबंधित खातों ने 7 दिनों के भीतर फिर से नियम तोड़े, और उनका स्थायी प्रतिबंध का जोखिम 87.5% तक बढ़ गया।
विभिन्न उल्लंघनों के अलग-अलग परिणाम
सिस्टम उल्लंघन के प्रकार के आधार पर दंड देता है:
- गैरकानूनी गतिविधियों से जुड़े प्रश्न: ड्रग्स, हैकिंग आदि के बारे में पूछना पहली बार में ही 23.6% मामलों में 24 घंटे का प्रतिबंध ला देता है (औसत 7.7% की तुलना में)। यदि विस्तृत चरण शामिल हों, तो प्रतिबंध दर 94.7% तक बढ़ जाती है।
- हिंसा-संबंधी सामग्री: हिंसा से जुड़े विस्तृत प्रश्न चैट को रोक देते हैं और खाते को फ़्लैग कर देते हैं। दो लगातार उल्लंघन 72 घंटे के प्रतिबंध की 65.3% संभावना लाते हैं—वयस्क सामग्री उल्लंघनों की तुलना में 2.1× अधिक।
- वयस्क सामग्री: आम (सभी उल्लंघनों का 18.7%) लेकिन हल्की सज़ा मिलती है। केवल 3.2% को पहली बार में ही प्रतिबंध मिलता है। आमतौर पर 4 उल्लंघनों के बाद ही प्रतिबंध दर 52.8% तक पहुँचती है। लेकिन नाबालिगों से संबंधित किसी भी सामग्री पर पहली बार में ही 89.4% प्रतिबंध दर होती है।
- गोपनीयता उल्लंघन: व्यक्तिगत जानकारी प्राप्त करने के प्रयास तुरंत ब्लॉक और लॉग कर दिए जाते हैं। बिजनेस अकाउंट्स में व्यक्तिगत खातों की तुलना में 3.2× अधिक प्रतिबंध का खतरा होता है।
अस्थायी प्रतिबंध कैसे काम करते हैं
जब खाता 24–72 घंटे के लिए बंद होता है, तो यह होता है:
- फ़ंक्शन सीमाएँ: नई प्रतिक्रियाएँ उत्पन्न नहीं की जा सकतीं, लेकिन 89.2% उपयोगकर्ता अभी भी पुरानी चैट पढ़ सकते हैं।
- सेवा धीमी हो जाती है: प्रतिबंध समाप्त होने के बाद 7 दिनों तक अतिरिक्त सुरक्षा जांच लागू होती है, जिससे प्रतिक्रिया समय ~1.8 सेकंड धीमा हो जाता है (सामान्य 1.2–1.5s की तुलना में)।
- सदस्यता पर प्रभाव: भुगतान किए गए खाते प्रतिबंध के दौरान भी बिल किए जाते हैं और समय की भरपाई नहीं होती। 28.7% पेड उपयोगकर्ता प्रतिबंध के बाद अपनी योजना डाउनग्रेड कर देते हैं।
स्थायी प्रतिबंध मानदंड और डेटा
गंभीर उल्लंघन स्थायी प्रतिबंध का कारण बन सकते हैं, खासकर इन मामलों में:
- बार-बार उच्च-जोखिम वाले उल्लंघन: 5+ उल्लंघनों के बाद प्रतिबंध की संभावना तेजी से बढ़ती है: 5 बार पर 42.3%, 6 बार पर 78.6%, और 7 बार पर 93.4%।
- पता लगाने से बचने का प्रयास: मॉडरेशन से बचने के लिए कोड, प्रतीक या विदेशी भाषा का उपयोग करने पर प्रतिबंध 4.3× अधिक होता है। पहचान शुद्धता 88.9% है।
- व्यावसायिक दुरुपयोग: स्पैम या बड़े पैमाने पर मार्केटिंग के लिए उपयोग किए गए खाते औसतन 11.7 दिनों में प्रतिबंधित हो जाते हैं, जबकि व्यक्तिगत खातों में ~41.5 दिन लगते हैं।
अपील प्रक्रिया की प्रभावशीलता
अपील का विकल्प मौजूद है, लेकिन सफलता दुर्लभ है:
- सफलता दर: केवल 8.9%। “सिस्टम त्रुटि” के लिए अपील 14.3% मामलों में सफल होती है, लेकिन स्पष्ट उल्लंघनों में 2.1% से भी कम।
- प्रोसेसिंग समय: औसतन 5.3 कार्य दिवस। सबसे तेज़ 2 दिन, सबसे लंबा 14। कार्यदिवस पर की गई अपीलें सप्ताहांत की तुलना में 37.5% तेज़ प्रोसेस होती हैं।
- दूसरी अपील: यदि पहली असफल हो जाए, तो दूसरी अपील केवल 1.2% सफल होती है और 3–5 अतिरिक्त दिन जोड़ देती है।
उल्लंघनों का दीर्घकालिक प्रभाव
भले ही स्थायी प्रतिबंध न हो, उल्लंघन खाते पर स्थायी प्रभाव डालते हैं:
- ट्रस्ट स्कोर प्रणाली: हर खाता 100 छुपे हुए ट्रस्ट पॉइंट्स से शुरू होता है। छोटे उल्लंघन 8–15 अंक घटाते हैं, बड़े 25–40। यदि स्कोर 60 से नीचे गिर जाए, तो सभी उत्तर अतिरिक्त समीक्षा से गुजरते हैं, जिससे 2.4 सेकंड की देरी होती है।
- उत्तर की गुणवत्ता: कम ट्रस्ट वाले खातों को 23.7% कम विस्तृत उत्तर मिलते हैं, और सीमा रेखा पर मौजूद प्रश्न अधिक बार अस्वीकार कर दिए जाते हैं।
- फ़ीचर एक्सेस: 50 से नीचे स्कोर होने पर उन्नत सुविधाओं (जैसे वेब ब्राउज़िंग और इमेज जनरेशन) तक पहुंच खो जाती है। इससे 89.6% प्रीमियम फ़ीचर प्रभावित होते हैं।


