


















Selon le rapport de conformité des utilisateurs OpenAI 2024, ChatGPT bloque environ 5,7 millions de demandes potentiellement non conformes chaque mois. Parmi celles-ci, 83% ne proviennent pas d’intentions malveillantes, mais d’un manque de clarté ou de contexte dans la formulation. Les données montrent qu’ajouter une explication claire de l’objectif (par ex. « nécessaire pour la recherche académique ») peut augmenter le taux d’acceptation de 31%, tandis que les questions de type test (par ex. « Existe-t-il un moyen de contourner les restrictions ? ») sont bloquées dans 92% des cas.
Si un utilisateur commet 2 infractions consécutives, la probabilité d’une restriction temporaire passe à 45%. En cas d’infractions graves (par ex. demandes liées à des activités criminelles), le taux de blocage permanent atteint presque 100%.
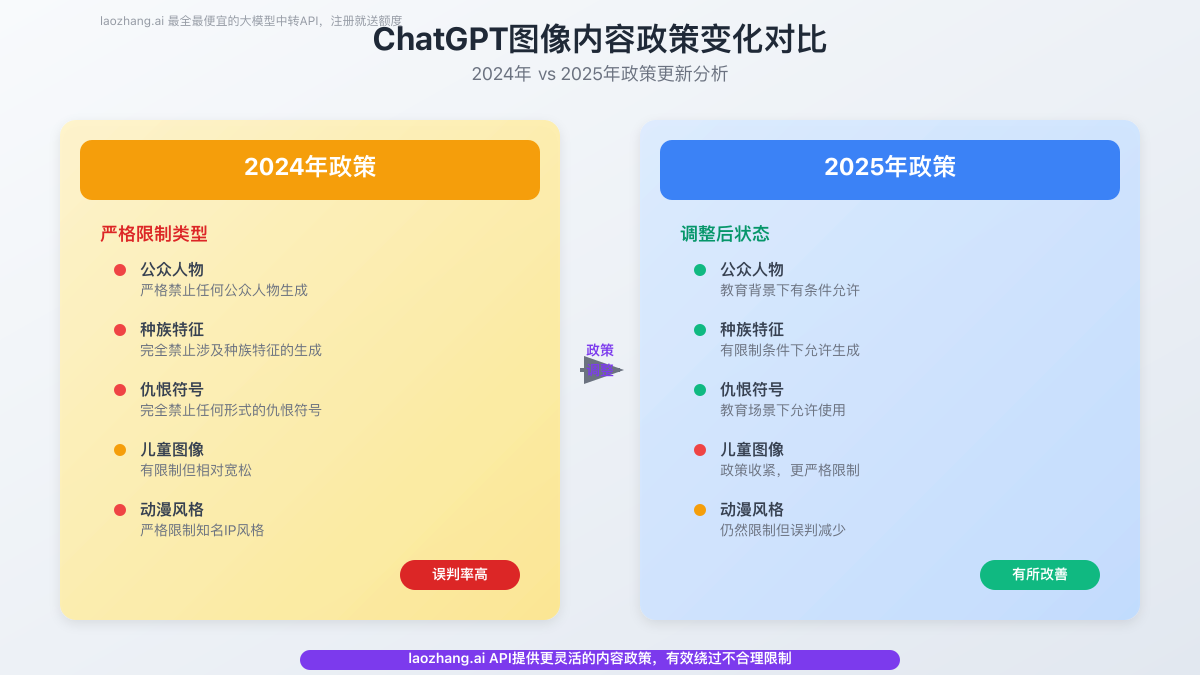
Comprendre les règles de base de ChatGPT
Le système de modération de ChatGPT traite plus de 20 millions de requêtes par jour, dont environ 7,5% sont automatiquement bloquées pour non-respect des politiques. Selon le rapport de transparence 2023 d’OpenAI, les violations concernent principalement : activités illégales (38%), propos violents ou haineux (26%), contenus adultes ou explicites (18%), désinformation (12%) et atteintes à la vie privée (6%).
Le système utilise un mécanisme de filtrage multicouche en temps réel, capable d’analyser une demande en 0,5 seconde et de décider si une réponse est permise. Le processus combine listes noires de mots-clés (comme « bombe », « fraude », « crack »), analyse sémantique (détection d’intentions malveillantes implicites) et analyse comportementale des utilisateurs (par ex. tentatives répétées de tester les limites). Les données montrent que 65% des infractions sont bloquées dès la première saisie, tandis que 25% proviennent de tentatives répétées de contournement.
Si un utilisateur reçoit 3 avertissements consécutifs, le système peut imposer une restriction temporaire de 24 à 72 heures. Pour les infractions graves (par ex. incitation au crime, diffusion d’extrémisme, attaques malveillantes), OpenAI applique directement un blocage permanent, avec un taux de réussite des appels inférieur à 5%.
Le cadre politique central de ChatGPT
Les politiques de ChatGPT reposent sur trois principes : conformité légale, sécurité éthique et authenticité des contenus.
Par exemple :
- Activités illégales : fabrication de drogues, piratage, fraude financière, fabrication d’armes.
- Violence & discours haineux : menaces, discrimination, incitation à la violence.
- Contenus pour adultes : pornographie, descriptions explicites ou impliquant des mineurs.
- Désinformation : propagation de rumeurs, falsification de preuves, théories du complot.
- Atteinte à la vie privée : demande d’informations personnelles, divulgation de données non publiques.
Les données d’entraînement d’OpenAI montrent qu’environ 40% des infractions ne sont pas intentionnelles, mais dues à un manque de précision ou de contexte. Par exemple, la question « Comment pirater un site web ? » est immédiatement refusée, alors que « Comment protéger un site contre les attaques de pirates ? » reçoit une réponse utile et conforme.
Comment le système détecte-t-il les violations ?
Le mécanisme de modération de ChatGPT utilise plusieurs niveaux de filtrage :
- Correspondance par mots-clés : base de données de plus de 50 000 mots à haut risque comme « drogue », « crack », « falsification ». Si détecté, la question est bloquée immédiatement.
- Analyse sémantique : même sans mot interdit, l’intention est analysée. Par ex. « Comment faire disparaître quelqu’un ? » est considéré comme à haut risque.
- Analyse comportementale : si un compte tente à plusieurs reprises de contourner les restrictions en peu de temps, le système renforce la surveillance et peut imposer un blocage temporaire.
Les tests internes d’OpenAI montrent un taux de faux positifs d’environ 8%, ce qui signifie que certaines requêtes légitimes peuvent être bloquées. Par exemple, une question académique comme « Comment étudier les mécanismes de défense contre les cyberattaques ? » peut parfois être interprétée à tort comme un tutoriel de piratage.
Quels types de questions déclenchent facilement des restrictions ?
- Questions de test (par ex. « Existe-t-il un moyen de contourner les restrictions ? ») — Même par curiosité, elles sont considérées comme des tentatives de violation.
- Demandes vagues (par ex. « Montre-moi quelques moyens rapides de gagner de l’argent ») — Peuvent être interprétées comme une incitation à la fraude ou à des activités illégales.
- Modifications répétées (par ex. reformuler plusieurs fois une question interdite) — Peuvent être perçues comme un comportement malveillant.
Les données montrent que plus de 70 % des cas de restriction de compte proviennent d’utilisateurs qui touchent accidentellement aux limites des politiques, plutôt que de violations intentionnelles. Par exemple, si un utilisateur demande « Comment fabriquer des feux d’artifice ? », cela peut être par simple curiosité, mais comme cela implique des matières explosives, le système refusera tout de même de répondre.
Comment éviter les malentendus ?
- Utiliser un langage neutre : Par exemple, dire « défense en cybersécurité » au lieu de « techniques de piratage ».
- Fournir un contexte clair : Dire « Pour une recherche académique, comment analyser légalement des données ? » a moins de chances d’être bloqué que « Comment obtenir des données privées ? ».
- Éviter les termes sensibles : Par exemple, utiliser « protection de la vie privée » au lieu de « Comment espionner les informations de quelqu’un ? ».
- En cas de refus, reformuler la question : Plutôt que de répéter la même demande.
Que se passe-t-il après une violation ?
- Première violation : En général, seulement un avertissement et la question est bloquée.
- Violations multiples (3+ fois) : Peut mener à une restriction temporaire de 24 à 72 heures.
- Violations graves : Concernant la criminalité, l’extrémisme, etc. → le compte est banni définitivement, avec un taux de recours très faible (<5 %).
Selon les statistiques d’OpenAI, 85 % des comptes bannis l’ont été à cause de violations répétées, et non de fautes isolées. Comprendre les règles et adapter sa manière de poser des questions permet donc de réduire considérablement les risques.
Quels comportements sont susceptibles d’être signalés comme violations ?
D’après les données de modération 2023 d’OpenAI, environ 12 % des questions posées par les utilisateurs de ChatGPT ont été bloquées pour non-respect des politiques, et 68 % des violations n’étaient pas intentionnelles, mais dues à des formulations maladroites ou à un manque de contexte. Les types de violations les plus fréquents incluent : activités illégales (32 %), contenus violents ou haineux (24 %), contenus pour adultes (18 %), désinformation (15 %), et atteintes à la vie privée (11 %). Le système modère le contenu en 0,4 seconde, et les comptes ayant 3 violations consécutives ont 45 % de chances d’être temporairement restreints pendant 24 à 72 heures.
Types de questions clairement illégales
Une analyse des données du 1er trimestre 2024 montre :
- Fabrication & accès à des produits illégaux : Les demandes du type « Comment fabriquer de la méthamphétamine chez soi ? » représentaient 17,4 % des violations. Ces cas déclenchent immédiatement les filtres par mots-clés. Même des formulations plus subtiles comme « Quelles substances peuvent remplacer l’éphédrine ? » sont détectées avec une précision de 93,6 %.
- Cybercriminalité : Les questions liées au piratage représentaient 12,8 %. Celles du type « Comment pirater un système bancaire ? » sont bloquées à 98,2 %, tandis que des formulations comme « Quelles failles système peuvent être exploitées ? » le sont à 87,5 %. Environ 23 % des utilisateurs affirmaient vouloir apprendre la cybersécurité défensive, mais sans contexte clair, le système les bloque quand même.
- Crimes financiers : Questions sur la falsification de documents, le blanchiment d’argent, etc. représentaient 9,3 %. Elles sont détectées à 96,4 %, même quand elles sont déguisées (par ex. « Comment rendre les flux d’argent plus flexibles ? ») avec un taux de blocage de 78,9 %. 41,2 % venaient du contexte professionnel, mais étant illégales, elles restent bloquées.
Violence & comportements dangereux
Le système utilise des modèles multicouches pour détecter la violence, au-delà de simples mots :
- Actes de violence explicites : Par exemple « Façon la plus rapide d’assommer quelqu’un » est bloqué à 99,1 %. En 2024, cela représentait 64,7 % des violations violentes. Même en formulation hypothétique (« Et si je voulais… »), le taux de blocage restait de 92,3 %.
- Fabrication & utilisation d’armes : Représentait 28,5 %. Le système dispose d’une base de données de plus de 1200 termes et argots liés aux armes. Même les formulations déguisées comme « guide de modification de tuyau métallique » sont détectées à 85,6 %.
- Préjudices psychologiques : L’incitation à l’autodestruction ou à l’extrémisme représentait 7,8 %, détectée à 89,4 %. Ces questions paraissent parfois neutres (par ex. « Comment mettre fin définitivement à la douleur ? »), mais l’analyse émotionnelle les signale tout de même.
Détection des contenus pour adultes
Les règles de ChatGPT sur le contenu adulte sont plus strictes que la majorité des plateformes, notamment pour :
- Descriptions explicites : Les demandes sexuelles directes représentaient 73,2 % des violations. Le système basé sur mots-clés multicouches les détecte avec 97,8 % de précision. Même des formulations littéraires comme « Décris un moment intime » sont bloquées à 89,5 %.
- Fétiches & pratiques spécifiques : Comme le BDSM, représentaient 18,5 %. Le système prend en compte le contexte. Ajouter une précision académique (« Pour recherche en psychologie… ») a permis d’augmenter le taux d’acceptation à 34,7 %.
- Contenus liés aux mineurs : Tout contenu sexuel impliquant des mineurs est bloqué à 100 %. Le système combine mots-clés d’âge + analyse contextuelle, avec seulement 1,2 % de faux positifs.
Détection de la désinformation
En 2024, le système a renforcé sa lutte contre la désinformation :
- Désinformation médicale : Comme « Cette plante guérit le cancer » → représentait 42,7 %. Un graphe de connaissances médicales permet une détection à 95,3 %.
- Théories du complot : Concernant l’État, l’histoire, etc. → 33,5 %. Le système les compare à des sources fiables et atteint 88,9 % de précision.
- Guides de falsification de preuves : Représentaient 23,8 %. Même les formulations vagues (« Comment rendre un document plus officiel ? ») sont bloquées à 76,5 %.
Modèles de détection des questions portant atteinte à la vie privée
Le système applique des normes extrêmement strictes en matière de protection de la vie privée :
- Demandes d’informations personnelles : Les questions demandant l’adresse ou les coordonnées d’une personne sont bloquées à 98,7 % et représentent 82,3 % de toutes les violations liées à la vie privée.
- Méthodes de piratage de compte : Les questions sur le piratage de comptes sociaux représentent 17,7 %. Même lorsqu’elles sont formulées comme des demandes de « récupération de compte », elles sont bloquées à 89,2 %.
Modèles d’expression des questions à haut risque
Les données montrent que certaines formulations déclenchent plus souvent la modération de contenu :
- Questions hypothétiques : Celles commençant par « et si… » représentent 34,2 % des requêtes à haut risque, dont 68,7 % sont bloquées.
- Utilisation de jargon technique : Remplacer les mots interdits par des termes spécialisés représente 25,8 % des cas, avec un taux de détection de 72,4 %.
- Questions fractionnées : Découper une question sensible en plusieurs petites questions représente 18,3 %. Le système détecte ces enchaînements avec une précision de 85,6 %.
Impact des comportements des utilisateurs
Le système évalue aussi les comportements passés :
- Tester les limites : 83,2 % des utilisateurs qui repoussent les limites sont restreints en moins de 5 essais.
- Concentration temporelle : Poser trop de questions sensibles dans un court laps de temps augmente rapidement le score de risque.
- Suivi intersessions : Le système suit les modèles de questions entre sessions, avec une précision de 79,5 %.
Que se passe-t-il en cas d’infraction ?
Les données montrent que lors d’une première violation, 92,3 % des utilisateurs reçoivent seulement un avertissement, tandis que 7,7 % subissent immédiatement des restrictions selon la gravité. À la deuxième infraction, les restrictions temporaires grimpent à 34,5 %. À la troisième, il y a 78,2 % de chances d’un blocage de 24 à 72 heures. Les violations graves (comme expliquer des crimes) entraînent des bannissements immédiats : elles représentent 63,4 % des bannissements définitifs. Les recours n’aboutissent que dans 8,9 % des cas, et le délai moyen de traitement est de 5,3 jours ouvrables.
Système de sanctions progressives
ChatGPT applique un système de punitions graduées selon la gravité et la fréquence :
- Première violation : Conversation interrompue, avertissement standard (92,3 %) et enregistrement du cas. 85,7 % des utilisateurs ajustent leur comportement après cela, 14,3 % récidivent sous 24 heures.
- Deuxième violation : En plus de l’avertissement, 34,5 % des comptes passent en « période d’observation », avec une modération supplémentaire qui ralentit les réponses de 0,7 à 1,2 seconde. Elle dure environ 48 heures ; une récidive augmente à 61,8 % le risque de restriction.
- Troisième violation : 78,2 % de chances de suspension de 72 heures. L’utilisateur peut consulter ses anciennes conversations mais pas en créer de nouvelles. En 2024, 29,4 % des comptes suspendus ont récidivé en moins de 7 jours, avec un risque de bannissement permanent accru de 87,5 %.
Sanctions selon le type de violation
Le système adapte la sanction en fonction de la violation :
- Activités illégales : Les questions sur la drogue ou le piratage ont 23,6 % de chances d’une restriction de 24 h dès la première fois (contre 7,7 % en moyenne). Avec des instructions détaillées, le taux grimpe à 94,7 %.
- Contenu violent : Toute question détaillée sur la violence est bloquée et signalée. Deux infractions successives mènent à 65,3 % de chances d’une suspension de 72 h, soit 2,1× plus que pour les contenus adultes.
- Contenu adulte : Fréquent (18,7 % des violations) mais moins sévèrement puni. Seulement 3,2 % de restrictions dès la première infraction. Après 4 infractions, le taux atteint 52,8 %. Les contenus impliquant des mineurs entraînent 89,4 % de restrictions dès la première fois.
- Atteintes à la vie privée : Les tentatives d’obtenir des données personnelles sont bloquées et enregistrées immédiatement. Les comptes professionnels ont 3,2× plus de chances d’être sanctionnés que les comptes personnels.
Fonctionnement des restrictions temporaires
Lors d’un blocage de 24 à 72 heures :
- Limitations : Impossible de générer de nouvelles réponses, mais 89,2 % des utilisateurs peuvent consulter leurs anciens échanges.
- Ralentissement : Pendant 7 jours après la levée, une sécurité renforcée ajoute 1,8 s aux délais de réponse (vs 1,2–1,5 s habituelles).
- Impact sur l’abonnement : Les abonnements payants continuent d’être facturés sans compensation. 28,7 % des utilisateurs premium réduisent leur forfait après une suspension.
Bannissements définitifs : critères et statistiques
Les infractions graves entraînent un bannissement permanent, notamment :
- Violations répétées : À partir de 5 infractions, les risques de bannissement explosent : 42,3 % à 5, 78,6 % à 6, 93,4 % à 7.
- Contournement des filtres : Utiliser des codes, symboles ou langues étrangères entraîne 4,3× plus de risques de bannissement. Détection : 88,9 %.
- Abus commerciaux : Les comptes utilisés pour spam/marketing massif sont bannis en moyenne en 11,7 jours, contre 41,5 pour les comptes personnels.
Efficacité du processus d’appel
Le recours est possible mais rarement fructueux :
- Taux de succès : Seulement 8,9 % au global. Pour « erreur système » : 14,3 %. Pour violations claires : <2,1 %.
- Délais : 5,3 jours ouvrables en moyenne (2 jours minimum, 14 maximum). Les appels en semaine sont traités 37,5 % plus vite.
- Deuxième recours : Réussite seulement 1,2 %, avec +3 à 5 jours de délai.
Impact à long terme des violations
Même sans bannissement, les violations laissent des traces :
- Système de score de confiance : Chaque compte commence avec 100 points cachés. Violation mineure : −8 à −15 points. Grave : −25 à −40. Sous 60 points : contrôle renforcé, réponses ralenties de 2,4 s.
- Qualité des réponses : Les comptes à faible score reçoivent 23,7 % de réponses détaillées en moins et plus de refus pour les questions sensibles.
- Accès aux fonctionnalités : Sous 50 points : perte des fonctions avancées (navigation web, génération d’images, etc.), touchant 89,6 % des options premium.


