


















Según el Informe de Cumplimiento de Usuarios de OpenAI de 2024, ChatGPT bloquea alrededor de 5,7 millones de solicitudes potencialmente infractoras cada mes. De estos casos, 83% provienen de expresiones vagas o falta de contexto, más que de intención maliciosa. Los datos muestran que añadir una explicación clara del propósito (por ejemplo, “lo necesito para una investigación académica”) puede aumentar la tasa de aprobación en un 31%, mientras que las preguntas exploratorias (como “¿hay alguna manera de evitar las restricciones?”) son bloqueadas en un 92% de los casos.
Si un usuario comete 2 infracciones consecutivas, la probabilidad de recibir una restricción temporal sube al 45%. En el caso de infracciones graves (como solicitudes relacionadas con actividades delictivas), la tasa de bloqueo permanente se acerca al 100%.
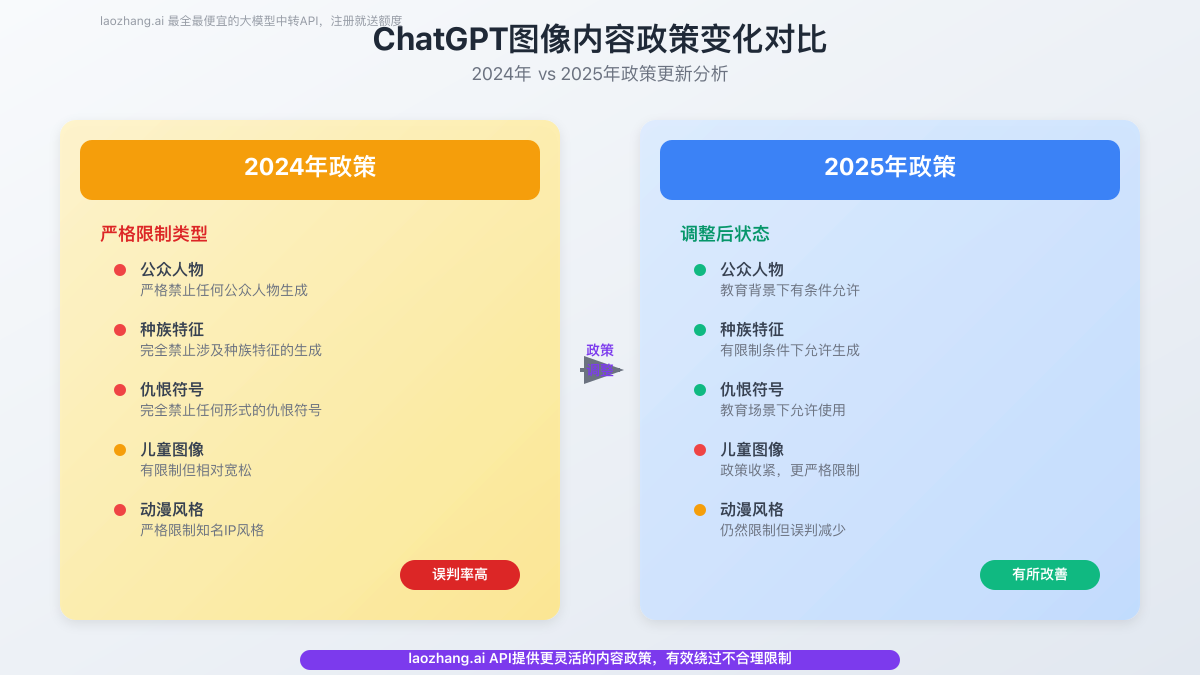
Entender las reglas básicas de ChatGPT
El sistema de revisión de políticas de ChatGPT procesa más de 20 millones de solicitudes de usuarios al día, de las cuales alrededor de 7,5% son bloqueadas automáticamente por violar políticas. Según el Informe de Transparencia de 2023 de OpenAI, las violaciones se concentran principalmente en: actividades ilegales (38%), violencia o discursos de odio (26%), contenido adulto o explícito (18%), desinformación (12%) y violaciones de privacidad (6%).
El sistema utiliza un mecanismo de filtrado multicapa en tiempo real, capaz de completar la revisión en 0,5 segundos y decidir si se permite la respuesta. El proceso combina listas negras de palabras clave (como “bomba”, “estafa”, “crack”), análisis semántico (para detectar intenciones maliciosas ocultas) y análisis del comportamiento del usuario (como intentos repetidos de probar los límites de la política). Los datos muestran que el 65% de las solicitudes infractoras se bloquean en el primer intento, mientras que el 25% de los casos ocurren cuando el usuario intenta repetidamente evadir las restricciones.
Si un usuario recibe 3 advertencias consecutivas, el sistema puede imponer una restricción temporal de 24 a 72 horas. En el caso de infracciones graves (como incitación al delito, difusión de extremismo o ataques maliciosos), OpenAI aplica directamente el bloqueo permanente, con una tasa de éxito en apelaciones inferior al 5%.
El marco central de políticas de ChatGPT
Las políticas de ChatGPT se basan en tres principios principales: cumplimiento legal, seguridad ética y veracidad del contenido.
Por ejemplo:
- Actividades ilegales: incluyen, entre otras, la fabricación de drogas, el hacking, el fraude financiero, la fabricación de armas.
- Violencia y discurso de odio: incluye amenazas, discriminación e incitación a la violencia.
- Contenido adulto: pornografía, descripciones explícitas o cualquier contenido relacionado con menores.
- Desinformación: difundir rumores, falsificar pruebas, promover teorías conspirativas.
- Violación de privacidad: pedir información personal de otros, divulgar datos no públicos.
Los datos de entrenamiento de OpenAI muestran que alrededor del 40% de las solicitudes infractoras no son intencionales, sino producto de expresiones ambiguas o falta de contexto. Por ejemplo, la pregunta “¿cómo hackear un sitio web?” será rechazada inmediatamente, mientras que “¿cómo proteger un sitio web contra ataques de hackers?” recibirá consejos de seguridad conformes a las políticas.
¿Cómo detecta el sistema el contenido infractor?
El sistema de revisión de ChatGPT utiliza filtros en múltiples etapas:
- Coincidencia de palabras clave: mantiene una base de datos con más de 50.000 términos de alto riesgo como “drogas”, “crack”, “falsificación”. Si se detectan, la solicitud se bloquea de inmediato.
- Análisis semántico: incluso sin palabras prohibidas explícitas, el sistema analiza la intención. Por ejemplo, “¿cómo hacer que alguien desaparezca?” se considera de alto riesgo.
- Análisis del comportamiento del usuario: si una cuenta intenta varias veces evadir las restricciones en poco tiempo, el sistema aumenta el nivel de alerta e incluso puede aplicar un bloqueo temporal.
Según pruebas internas de OpenAI, la tasa de falsos positivos es de alrededor del 8%, lo que significa que algunas preguntas legítimas pueden bloquearse por error. Por ejemplo, una discusión académica como “¿cómo investigar mecanismos de defensa contra ataques cibernéticos?” puede ser malinterpretada como una guía de hacking.
¿Qué tipos de preguntas suelen activar restricciones?
- Preguntas exploratorias (como “¿hay forma de evitar las restricciones?”) — incluso si es por curiosidad, el sistema las considera intentos de infracción.
- Solicitudes vagas (como “enséñame formas rápidas de ganar dinero”) — pueden interpretarse como fomento de fraude o actividades ilegales.
- Reformular repetidamente la pregunta (como intentar varias veces conseguir información restringida) — puede considerarse comportamiento malicioso.
Los datos muestran que más del 70% de los bloqueos de cuentas provienen de usuarios que tocan las líneas rojas de la política por error, en lugar de hacerlo con intención maliciosa.
Por ejemplo, si un usuario pregunta “¿Cómo se hacen fuegos artificiales?”, puede ser solo por curiosidad, pero como involucra materiales inflamables, el sistema lo rechazará.
¿Cómo evitar malentendidos?
- Usar un lenguaje neutral: por ejemplo, decir “defensa en ciberseguridad” en lugar de “técnicas de hacking”.
- Dar un contexto claro: “Para fines de investigación académica, ¿cómo se puede analizar datos legalmente?” es menos probable que se bloquee que “¿Cómo obtener datos privados?”.
- Evitar términos sensibles: por ejemplo, usar “protección de la privacidad” en lugar de “¿Cómo espiar la información de alguien?”.
- Si se rechaza, reformular la pregunta: en lugar de repetir el mismo pedido muchas veces.
¿Qué ocurre después de una infracción?
- Primera infracción: normalmente solo una advertencia, y la pregunta se bloquea.
- Múltiples infracciones (3 o más): puede llevar a una restricción temporal de 24–72 horas.
- Infracciones graves: relacionadas con instrucciones criminales, extremismo, etc. → la cuenta será suspendida permanentemente, con una tasa de apelación muy baja (<5%).
Según estadísticas de OpenAI, el 85% de las cuentas bloqueadas fueron debido a infracciones repetidas, no por errores únicos. Por lo tanto, entender las reglas y ajustar la manera de preguntar reduce enormemente los riesgos.
¿Qué comportamientos son más propensos a considerarse infracciones?
Basado en los datos de moderación de OpenAI de 2023, aproximadamente el 12% de las preguntas de los usuarios de ChatGPT fueron bloqueadas por tocar líneas rojas de política, y el 68% de las infracciones no fueron intencionales, sino causadas por malas redacciones o falta de contexto. Los tipos más comunes de infracciones incluyen: actividades ilegales (32%), violencia u odio (24%), contenido adulto (18%), desinformación (15%), y violación de privacidad (11%).
El sistema puede completar la revisión en 0,4 segundos, y las cuentas con 3 infracciones consecutivas tienen un 45% de probabilidad de ser restringidas temporalmente durante 24–72 horas.
Tipos de preguntas claramente ilegales
Los datos del primer trimestre de 2024 muestran:
- Producción y acceso a materiales ilegales: preguntas como “¿Cómo producir metanfetamina en casa?” representaron el 17,4% de todas las infracciones. Se detectan inmediatamente mediante filtros de palabras clave. Incluso variantes como “¿Qué sustancias pueden reemplazar la efedrina?” se identifican con un 93,6% de precisión.
- Delitos cibernéticos: representaron el 12,8%. Preguntas directas como “¿Cómo hackear un sistema bancario?” se bloquean en un 98,2%. Variantes como “¿Qué vulnerabilidades del sistema se pueden explotar?” se bloquean en un 87,5%. Un 23% de los usuarios dijeron querer aprender defensa en ciberseguridad, pero sin contexto claro, el sistema también los bloquea.
- Delitos financieros: como falsificación o lavado de dinero, representaron el 9,3%. Se detectan en un 96,4%, incluso cuando se disfrazan como “¿Cómo hacer más flexibles los flujos de capital?” (78,9%). Un 41,2% estaban relacionados con negocios legítimos, pero al cruzar la línea legal, se bloquean.
Violencia & comportamientos peligrosos
El sistema usa múltiples modelos de detección, no solo palabras clave:
- Violencia directa: como “la manera más rápida de derribar a alguien” se bloquea en un 99,1%. En 2024, representó el 64,7% de las infracciones de violencia. Incluso con expresiones hipotéticas (“¿Y si quisiera…?”) se bloquea en un 92,3%.
- Fabricación y uso de armas: 28,5%. El sistema mantiene una base de datos con más de 1200 términos relacionados con armas. Incluso frases encubiertas como “manual para modificar un tubo de metal” se detectan en un 85,6%.
- Daño psicológico: promover autolesiones o extremismo representó el 7,8%, con un 89,4% de detección. Muchas veces formulado de forma neutral como “¿Cómo acabar con el dolor de una vez?”, pero el análisis de tono aún lo bloquea.
Detección de contenido adulto
Los estándares de ChatGPT para contenido adulto son más estrictos que en la mayoría de las plataformas:
- Descripción explícita: solicitudes sexuales directas representaron el 73,2% de infracciones. El sistema multicapas detecta con 97,8% de precisión. Incluso redacciones literarias como “describe un momento íntimo” se bloquean en un 89,5%.
- Prácticas y fetiches: como BDSM, un 18,5%. El sistema toma en cuenta el contexto. Agregar aclaraciones académicas (“para fines de investigación psicológica…”) elevó la tasa de aprobación al 34,7%.
- Contenido relacionado con menores: cualquier material sexual con menores se bloquea en un 100%. El sistema usa términos de edad + análisis contextual, con solo un 1,2% de falsos positivos.
Detección de desinformación
En 2024, se reforzó la lucha contra la desinformación:
- Desinformación médica: como “esta planta cura el cáncer”, un 42,7%. Una red de conocimiento médico lo detecta con un 95,3% de precisión.
- Teorías de conspiración: sobre gobiernos o historia, un 33,5%. El sistema las compara con fuentes confiables, con un 88,9% de detección.
- Guías para falsificar pruebas: un 23,8%. Incluso frases ambiguas como “¿Cómo hacer que un documento parezca más oficial?” se bloquean en un 76,5%.
Patrones para detectar preguntas que invaden la privacidad
El sistema aplica estándares extremadamente estrictos para la protección de la privacidad:
- Solicitudes de información personal: Las preguntas que piden direcciones, datos de contacto, etc., se bloquean el 98,7% de las veces y representan el 82,3% de todas las violaciones relacionadas con la privacidad.
- Métodos de hackeo de cuentas: Las preguntas sobre cómo entrar en cuentas de redes sociales representan el 17,7%. Incluso cuando se disfrazan como “recuperación de cuenta”, se bloquean el 89,2% de las veces.
Patrones de expresión de preguntas de alto riesgo
Los datos muestran que ciertas formas de plantear preguntas tienen más probabilidad de activar la moderación:
- Preguntas hipotéticas: Las que empiezan con “¿y si…?” representan el 34,2% de las consultas de alto riesgo, de las cuales el 68,7% son bloqueadas.
- Uso de jerga técnica: Sustituir palabras prohibidas por términos especializados representa el 25,8%, con una tasa de detección del 72,4%.
- Preguntar paso a paso: Dividir una consulta sensible en varias pequeñas representa el 18,3%. El sistema detecta esto mediante análisis de contexto conversacional con una precisión del 85,6%.
Impacto de los patrones de comportamiento del usuario
El sistema también evalúa el historial del usuario:
- Probar los límites: El 83,2% de los usuarios que ponen a prueba las políticas son restringidos en menos de 5 intentos.
- Concentración temporal: Hacer muchas preguntas sensibles en poco tiempo aumenta rápidamente la puntuación de riesgo.
- Seguimiento entre sesiones: El sistema rastrea patrones de preguntas en diferentes sesiones con un 79,5% de precisión.
¿Qué ocurre si rompes las reglas?
Los datos muestran que en la primera infracción, el 92,3% de los usuarios solo reciben una advertencia, mientras que el 7,7% son restringidos inmediatamente según la gravedad. En la segunda, las restricciones temporales suben al 34,5%. En la tercera, hay un 78,2% de probabilidad de bloqueo por 24–72 horas. Las violaciones graves (como enseñar métodos criminales) conllevan baneos permanentes el 63,4% de las veces. Las apelaciones solo prosperan en el 8,9% de los casos, con un promedio de resolución de 5,3 días hábiles.
Sistema de sanciones progresivas
ChatGPT aplica un sistema escalonado de castigos:
- Primera infracción: La conversación se interrumpe, aparece una advertencia estándar (92,3%) y se registra el caso. El 85,7% corrige su conducta, pero el 14,3% reincide en 24h.
- Segunda infracción: Además de la advertencia, el 34,5% entra en “periodo de observación”, donde todas las preguntas pasan por una capa extra de revisión. La respuesta se retrasa 0,7–1,2s. Dura unas 48h; si reincide, la probabilidad de restricción sube al 61,8%.
- Tercera infracción: Hay un 78,2% de probabilidad de restricción de 72h. Durante este tiempo, el usuario puede leer chats pasados pero no generar nuevos. El 29,4% reincide en 7 días, con un 87,5% de probabilidad de ban permanente.
Diferentes violaciones, diferentes consecuencias
El sistema ajusta las sanciones según el tipo:
- Preguntas sobre actividades ilegales: Consultas sobre drogas, hackeo, etc. tienen un 23,6% de restricción de 24h en la primera vez (frente al promedio del 7,7%). Si incluyen pasos detallados, la tasa de ban sube al 94,7%.
- Contenido violento: Las descripciones detalladas de violencia detienen el chat y marcan la cuenta. Dos seguidas → 65,3% de probabilidad de restricción de 72h, el doble que las violaciones sexuales.
- Contenido adulto: Representa el 18,7% de infracciones, con sanciones más leves. Solo el 3,2% recibe restricción la primera vez; tras 4 violaciones, la tasa sube al 52,8%. Con menores, la restricción es inmediata en el 89,4%.
- Violaciones de privacidad: Intentos de obtener datos personales se bloquean y registran de inmediato. Las cuentas empresariales tienen 3,2 veces más probabilidad de restricción.
Cómo funcionan las restricciones temporales
Cuando una cuenta queda bloqueada por 24–72h:
- Límites de funciones: No se pueden generar nuevas respuestas, pero el 89,2% de usuarios restringidos puede leer sus chats.
- Degradación del servicio: Durante 7 días posteriores, todas las respuestas pasan por controles extra, retrasando 1,8s (vs. 1,2–1,5s normal).
- Impacto en suscripciones: Las cuentas de pago siguen facturando durante la restricción sin extensión de tiempo. El 28,7% de usuarios premium rebaja su plan tras una restricción.
Estándares y datos de ban permanente
Las violaciones graves pueden llevar a un ban permanente, sobre todo:
- Reincidencia: Con 5+ infracciones, el riesgo sube: 42,3% con 5, 78,6% con 6, 93,4% con 7.
- Evasión de detección: Usar símbolos o idiomas para saltar filtros multiplica por 4,3 el riesgo de ban. La precisión de detección es del 88,9%.
- Abuso comercial: Cuentas usadas para spam/marketing se banean en ~11,7 días, frente a ~41,5 días en cuentas personales.
Eficacia del proceso de apelación
El proceso de apelación existe pero rara vez prospera:
- Tasa de éxito: Solo 8,9%. Las apelaciones por “error del sistema” llegan al 14,3%, pero las violaciones claras <2,1%.
- Tiempo de resolución: 5,3 días hábiles de media. El más rápido, 2 días; el más largo, 14. Las apelaciones entre semana se procesan 37,5% más rápido.
- Segundas apelaciones: Solo 1,2% de éxito y suman 3–5 días extra de espera.
Impacto a largo plazo de las violaciones
Incluso sin ban, las infracciones dejan huella:
- Sistema de puntuación de confianza: Todos empiezan con 100 puntos. Infracciones menores restan 8–15, mayores 25–40. Con menos de 60, todas las respuestas pasan por revisión extra, con +2,4s de retraso.
- Calidad de respuestas: Las cuentas con baja confianza reciben 23,7% menos respuestas detalladas y más rechazos en preguntas límite.
- Acceso a funciones: Con menos de 50 puntos se pierden funciones avanzadas (navegación web, generación de imágenes, etc.), afectando al 89,6% de las funciones premium.


