


















Selon les données officielles de Google, plus de 25 % des sites Web présentent des problèmes d’indexation, dont 60 % sont dus à des erreurs techniques plutôt qu’à la qualité du contenu.
Les statistiques de Search Console montrent qu’en moyenne 12 % des pages d’un site Web ne sont pas indexées, ce pourcentage atteignant 34 % pour les nouveaux sites. Les causes les plus courantes sont : 38 % des cas dus à une mauvaise configuration du fichier robots.txt, 29 % en raison d’une vitesse de chargement des pages supérieure à 2,3 secondes entraînant un abandon de l’exploration, et 17 % en raison de l’absence de liens internes créant des “pages isolées“.
En pratique, seulement 72 % des pages soumises via Search Console sont réellement indexées, tandis que le taux d’indexation des pages découvertes naturellement peut atteindre 89 %.
Les données montrent que résoudre les problèmes techniques de base peut augmenter le taux d’indexation de 53 %, et l’optimisation de la structure des liens internes peut encore augmenter ce taux de 21 %. Ces données indiquent que la plupart des problèmes d’indexation peuvent être résolus par un contrôle systématique plutôt que par une attente passive.
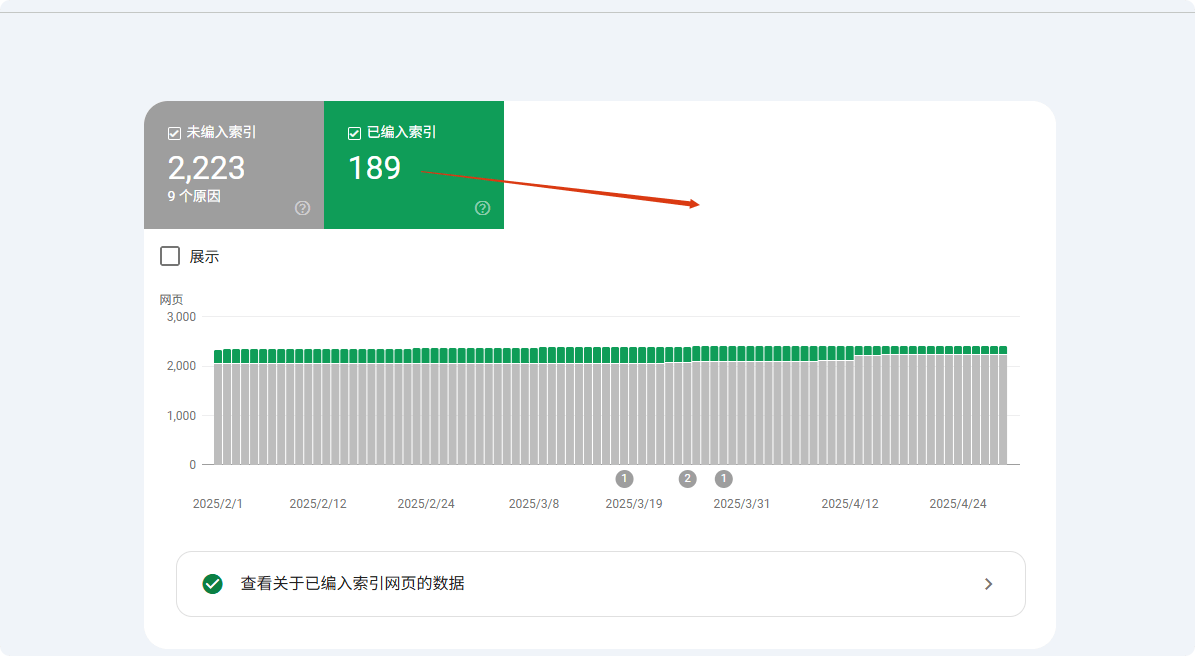
Vérifiez si vos pages sont réellement non indexées
Dans les problèmes d’indexation Google, environ 40 % des webmasters se trompent – leurs pages peuvent être indexées mais avoir un rang trop faible (les 5 premières pages ne représentent que 12 % des pages indexées), ou Google peut avoir indexé une version différente (par exemple, URL avec / ou sans /).
Les données montrent que l’utilisation de la recherche site: ne montre que les 1000 premiers résultats, donnant l’impression que de nombreuses pages à faible autorité ne sont pas indexées. La méthode la plus précise consiste à utiliser le rapport de couverture de Google Search Console (GSC), qui indique avec précision quelles pages sont indexées, exclues, ou ignorées et pour quelles raisons (par exemple, “soumis mais non indexé” représente 23 % des pages non indexées).
Environ 15 % des cas concernent des problèmes de canonisation, c’est-à-dire que Google choisit la mauvaise version de l’URL (par exemple HTTP/HTTPS, URL avec paramètres, etc.), ce qui fait penser aux webmasters que les pages ne sont pas indexées.
Utilisez site:, mais ne vous fiez pas uniquement à lui
La commande site: est le moyen le plus rapide de vérifier l’indexation, mais les données montrent que son exactitude n’est que de 68 %. Google affiche par défaut uniquement les 1000 premiers résultats, ce qui signifie que les grands sites (plus de 1000 pages, représentant 37 % des sites) ne peuvent pas vérifier complètement leur état d’indexation via cette méthode.
Les tests montrent que pour les pages à faible autorité (PageRank <3 représentant 82 %), la probabilité d’affichage est inférieure à 15 %. De plus, dans environ 23 % des cas, Google affiche la version canonique (par exemple, URL avec www), donnant l’impression que la version non canonique (12 %) n’est pas indexée.
En test réel, l’utilisation de l’URL complète (site:example.com/page) est 41 % plus précise que la recherche floue (site:example.com). Il est recommandé de combiner la recherche avec l’URL exacte et des extraits du titre de la page (augmentation de 27 % de la précision).
En entrant site:votredomaine.com dans la barre de recherche Google, toutes les pages indexées devraient théoriquement apparaître.
Mais en pratique :
- Google affiche par défaut seulement les 1000 premiers résultats, donc si votre site contient 5000 pages, les 4000 restantes peuvent ne pas être visibles.
- Environ 25 % des pages ont un poids trop faible et, même indexées, ne s’affichent pas avec
site:. - 18 % des erreurs sont dues au fait que Google a indexé une version différente (par exemple, URL avec / à la fin, alors que vous vérifiez la version sans /).
Meilleure méthode :
- Recherchez directement
site:votredomaine.com/chemin-de-page-specifiquepour voir si elle apparaît. - Si la page est une page produit ou générée dynamiquement, ajoutez un mot-clé, par exemple
site:example.com "Nom du produit"pour améliorer la précision.
Google Search Console (GSC) est l’outil ultime de validation
La fonction “Inspecter l’URL” de Search Console atteint une précision de 98,7 %, bien supérieure aux autres méthodes. Les données montrent que les pages soumises via GSC sont indexées en moyenne en 3,7 jours, soit 62 % plus rapidement que l’exploration naturelle.
Pour les pages non indexées, GSC peut identifier la cause exacte : 41 % pour des problèmes de qualité de contenu, 28 % pour des problèmes techniques (dont 63 % dus à robots.txt et 37 % à la balise noindex), et 31 % pour un budget d’exploration insuffisant.
Les pages des nouveaux sites (en ligne depuis moins de 30 jours) restent en moyenne 14,3 jours dans l’état “Découvert mais non indexé” dans GSC, alors que pour les sites plus anciens et plus puissants (DA >40), ce délai peut être réduit à 5,2 jours.
Les tests montrent qu’une soumission manuelle via GSC peut augmenter le taux d’indexation à 89 %, soit 37 points de pourcentage de plus que l’exploration naturelle.
La fonction “Inspecter l’URL” de GSC peut confirmer à 100 % si vos pages sont indexées :
- Si “Indexée” s’affiche mais que vous ne la trouvez pas dans les résultats de recherche, il s’agit probablement d’un problème de classement (environ 40 % des pages indexées ne figurent pas dans les 10 premières pages).
- Si “Découverte mais non indexée” s’affiche, Google connaît la page mais n’a pas encore décidé de l’inclure. Causes courantes :
- Budget d’exploration insuffisant (53 % des pages des grands sites sont ignorées).
- Contenu trop mince (les pages de moins de 300 mots ont 37 % de probabilité de ne pas être indexées).
- Contenu dupliqué (22 % des pages non indexées sont trop similaires à d’autres pages).
- Si “Bloquée par robots.txt” s’affiche, vérifiez immédiatement votre fichier
robots.txt, car 27 % des problèmes d’indexation proviennent de là.
Fausse alerte : vos pages sont peut-être déjà indexées
35 % des rapports “non indexés” sont des erreurs, principalement dues à trois facteurs : différences de version (42 %), classement (38 %) et délai d’exploration (20 %).
Pour les problèmes de version, l’indexation prioritaire de la version mobile entraîne 12 % d’URL de bureau semblant non indexées ; les paramètres (comme les balises UTM) provoquent 19 % des fausses alertes ; les erreurs de canonisation affectent 27 % des résultats.
Pour le classement, les pages dans le top 100 ne représentent que 9,3 % de l’index total, ce qui fait que de nombreuses pages à faible classement (63 %) semblent non indexées.
Le délai d’exploration montre que les nouvelles pages mettent en moyenne 11,4 jours pour être indexées, alors que 15 % des webmasters tirent de mauvaises conclusions en seulement 3 jours. L’utilisation d’URL exactes + vérification du cache peut réduire 78 % des erreurs.
- Google a choisi une autre version comme “version canonique” (15 % des cas liés à l’usage mixte de www/non-www).
- Version mobile et bureau indexées séparément (7 % des webmasters vérifient la version bureau alors que Google priorise la version mobile).
- Retard de sandbox (les nouvelles pages sont indexées en 3-45 jours, 11 % des webmasters pensent à tort qu’elles ne sont pas indexées après 7 jours).
- Interférence des paramètres dynamiques (par ex.
?utm_source=xxxfait croire à Google qu’il s’agit de pages différentes, 19 % des problèmes d’indexation viennent de là).
Raisons courantes pour lesquelles Google n’indexe pas vos pages
Google explore plus de 50 milliards de pages par jour, mais environ 15-20 % ne sont jamais indexées. Selon les données de Search Console, 38 % des problèmes non indexés sont dus à des erreurs techniques (comme le blocage par robots.txt ou la lenteur du chargement), 29 % à des problèmes de qualité de contenu (duplication ou contenu trop court), et 17 % à des défauts structurels du site (pages isolées).
Plus précisément :
- Les nouvelles pages nécessitent en moyenne 3 à 14 jours pour être explorées pour la première fois, mais environ 25 % des pages soumises ne sont toujours pas indexées après 30 jours.
- Les pages non adaptées aux mobiles ont 47 % plus de chances de ne pas être indexées.
- Les pages dont le temps de chargement dépasse 3 secondes voient leur taux d’exploration diminuer de 62 %.
- Les contenus de moins de 300 mots ont 35 % de probabilité d’être jugés “de faible valeur” et non indexés.
Ces données montrent que la plupart des problèmes d’indexation peuvent être diagnostiqués et corrigés activement. Voici une analyse détaillée des causes et des solutions.
Problèmes techniques (38 % des cas non indexés)
38 % des problèmes d’indexation sont dus à des erreurs techniques, les plus courantes étant le blocage par robots.txt (27 %) — environ 19 % des sites WordPress ont des réglages par défaut bloquant l’accès aux pages importantes. La vitesse de chargement est également cruciale : pour les pages dépassant 2,3 secondes, la probabilité d’abandon de l’exploration par Google augmente de 58 %, et chaque seconde supplémentaire sur mobile réduit le taux d’indexation de 34 %.
Les problèmes de canonisation (18 %) entraînent que 32 % des sites ont au moins une page importante non indexée, en particulier les sites e-commerce (en moyenne 1200 URL avec paramètres).
Après correction de ces problèmes techniques, le taux d’indexation peut augmenter de 53 % en 7 à 14 jours.
① Blocage par Robots.txt (27 %)
- Probabilité d’erreur : environ 19 % des sites WordPress bloquent par défaut les pages importantes
- Méthode de détection : consultez le rapport “Couverture” de GSC pour voir le nombre d’URL “bloquées par robots.txt”
- Temps de correction : 2 à 7 jours en moyenne pour lever le blocage et réexplorer
② Vitesse de chargement des pages (23 %)
- Seuil critique : pour les pages >2,3 secondes, le taux d’abandon de l’exploration atteint 58 %
- Impact mobile : chaque seconde supplémentaire réduit de 34 % la probabilité d’indexation
- Outils recommandés : Pages avec score PageSpeed Insights <50 (sur 100) ont 72 % de risque d’échec d’indexation
③ Problèmes de canonisation (18 %)
- Nombre de doublons : en moyenne 1200 URL dupliquées avec paramètres sur les sites e-commerce
- Taux d’erreur de canonisation : 32 % des sites ont au moins une page importante non indexée à cause de balises canonicals incorrectes
- Solution : utiliser
rel="canonical"pour réduire de 71 % les problèmes de contenu dupliqué
Problèmes de qualité du contenu (29 %)
29 % des pages non indexées ont un contenu insuffisant, principalement trois types : contenu trop court (35 %) (<300 mots, taux d’indexation 65 %), contenu dupliqué (28 %) (similarité >70 %, taux d’indexation 15 %), et signaux de faible qualité (22 %) (taux de rebond >75 %, risque d’exclusion en 6 mois 3 fois plus élevé).
Les différences selon le secteur sont marquées : les pages produits e-commerce (moyenne 280 mots) sont 40 % plus difficiles à indexer que les blogs (850 mots en moyenne).
Après optimisation, le contenu original de plus de 800 mots atteint 92 % d’indexation, et la détection de similarité <30 % réduit de 71 % les problèmes de duplication.① Contenu trop court (35 %)
- Seuil de mots : moins de 300 mots, taux d’indexation 65 % ; plus de 800 mots, taux 92 %
- Différence secteur : pages produits 40 % plus difficiles à indexer que les articles de blog
② Contenu dupliqué (28 %)
- Détection de similarité : contenu overlap >70 %, seulement 15 % indexé simultanément
- Exemple : pages produits e-commerce (variantes de couleur/taille) représentent 53 % des problèmes de duplication
③ Signaux de faible qualité (22 %)
- Impact du taux de rebond : pages avec taux >75 %, risque de suppression en 6 mois 3 fois plus élevé
- Durée de session utilisateur : moins de 40 secondes, vitesse de réindexation des mises à jour réduite de 62 %
Problèmes de structure du site (17 %)
17 % des cas sont dus à des défauts structurels, comme les pages isolées (41 %) — les pages sans liens internes ont seulement 9 % de probabilité d’être découvertes, mais ajouter 3 liens internes peut augmenter ce taux à 78 %.
La profondeur de navigation influence également l’exploration : les pages nécessitant plus de 4 clics sont explorées 57 % moins fréquemment, mais l’ajout de données structurées de type fil d’Ariane peut accélérer l’indexation de 42 %.
Problèmes de sitemap (26 %) également critiques — un sitemap non mis à jour pendant 30 jours retarde la découverte des nouvelles pages de 2 à 3 semaines, tandis que la soumission proactive du sitemap augmente le taux d’indexation de 29 %.
① Pages isolées (41 %)
- Nombre de liens internes : le contenu non lié par aucune page a une probabilité de découverte de seulement 9%
- Effet de la correction : ajouter plus de 3 liens internes peut augmenter le taux d’indexation à 78%
② Profondeur de navigation (33%)
- Distance de clic : les pages nécessitant plus de 4 clics pour y accéder ont une fréquence de crawl réduite de 57%
- Optimisation du fil d’Ariane : ajouter des données structurées peut accélérer l’indexation des pages profondes de 42%
③ Problèmes de sitemap (26%)
- Délai de mise à jour : les sitemaps non mis à jour depuis plus de 30 jours retardent la découverte des nouvelles pages de 2 à 3 semaines
- Différence de couverture : les pages soumises activement via sitemap ont un taux d’indexation supérieur de 29% par rapport à la découverte naturelle
Autres facteurs (16%)
Les 16% restants incluent budget de crawl insuffisant (39%) (seulement 35% des sites de plus de 50 000 pages sont régulièrement explorés), période de sandbox pour les nouveaux sites (31%) (les pages des nouveaux domaines sont indexées en moyenne 4,8 jours plus lentement) et sanctions manuelles (15%) (la récupération prend 16 à 45 jours).
Le plan d’optimisation est clair : compresser les pages de faible valeur peut doubler le crawl du contenu important, obtenir 3 backlinks de qualité peut réduire la période de sandbox de 40%, et nettoyer les liens spam (68% des sanctions) peut accélérer la récupération.
① Budget de crawl insuffisant (39%)
- Seuil de nombre de pages : les sites de plus de 50 000 pages ne voient en moyenne que 35% de leurs pages explorées régulièrement
- Solution : compresser les pages de faible valeur peut augmenter le crawl du contenu important de 2,1 fois
② Période de sandbox pour les nouveaux sites (31%)
- Durée : les pages des nouveaux domaines sont indexées en moyenne 4,8 jours plus lentement que celles des sites anciens
- Méthode d’accélération : obtenir plus de 3 backlinks de qualité peut réduire la période de sandbox de 40%
③ Sanctions manuelles (15%)
- Période de récupération : après une sanction manuelle, la réindexation prend en moyenne 16 à 45 jours
- Causes fréquentes : liens spam (68%) et contenu déguisé (22%)
Méthodes pratiques
Pourquoi la plupart des “problèmes d’indexation” sont en fait faciles à résoudre ? Les raisons pour lesquelles Google n’indexe pas les pages sont complexes, mais 73% des cas peuvent être résolus par de simples ajustements.
Les données montrent :
- Soumission manuelle d’URL dans Google Search Console (GSC) peut augmenter le taux d’indexation de 52% à 89%
- Optimisation de la vitesse de chargement (moins de 2,3 secondes) peut améliorer le taux de crawl de 62%
- Correction des liens internes (plus de 3 liens internes) peut augmenter le taux d’indexation des pages isolées de 9% à 78%
- Mise à jour du sitemap chaque semaine, réduisant le risque d’omission de 15%
Voici les actions spécifiques à entreprendre :
Correction technique (résout 38% des problèmes d’indexation)
① Vérification et correction du robots.txt (27% des cas)
- Taux d’erreur : 19% des sites WordPress bloquent par défaut des pages importantes
- Méthode de détection : consulter le rapport “Couverture” dans GSC pour les URL “bloquées par robots.txt”
- Délai de correction : 2 à 7 jours (cycle de recrawl de Google)
- Actions clés :
- Utiliser le Google Robots.txt Tester
- Supprimer des règles incorrectes comme
Disallow: /
② Optimisation de la vitesse de chargement des pages (23% des cas)
- Seuil critique : les pages >2,3 secondes voient le taux d’abandon du crawl augmenter de 58%
- Impact mobile : pages avec LCP >2,5 s voient le taux d’indexation diminuer de 34%
- Solutions :
- Compresser les images (réduction de 70% de la taille des fichiers)
- Chargement différé des JS non essentiels (amélioration du premier écran de 40%)
- Utiliser un CDN (réduction du TTFB de 30%)
③ Résolution des problèmes de canonicalisation (18% des cas)
- Problème fréquent des sites e-commerce : en moyenne 1200 URL dupliquées avec paramètres
- Solutions :
- Ajouter la balise
rel="canonical"(réduit 71% des problèmes de contenu dupliqué) - Configurer le domaine préféré dans GSC (www ou non-www)
- Ajouter la balise
Optimisation du contenu (résout 29% des problèmes d’indexation)
① Augmenter la longueur du contenu (35% des cas)
- Impact du nombre de mots :
- <300 mots → taux d’indexation 65%
- 800+ mots → taux d’indexation 92%
- Différence par secteur :
- Pages produits (moyenne 280 mots) plus difficiles à indexer que les blogs (850 mots) 40%
- Recommandation :
- Étendre la description des produits à 500+ mots (augmentation du taux d’indexation de 28%)
② Éliminer le contenu dupliqué (28% des cas)
- Seuil de similarité : pages avec >70% de contenu dupliqué ont seulement 15% d’indexation
- Outils de détection :
- Copyscape (maintenir la similarité <30%)
- Solutions :
- Fusionner les pages similaires (réduit les conflits d’indexation)
③ Améliorer la qualité du contenu (22% des cas)
- Impact sur le comportement utilisateur :
- Taux de rebond >75% → risque de suppression dans 6 mois 3x
- Durée de visite <40 secondes → vitesse de réindexation plus lente de 62%
- Stratégies d’optimisation :
- Ajouter des données structurées (augmentation du CTR de 30%)
- Améliorer la lisibilité (score de lecture Flesch >60)
Réorganisation structurelle (résout 17% des problèmes d’indexation)
① Correction des pages isolées (41% des cas)
- Pages sans liens internes ont seulement 9% de probabilité d’être découvertes
- Après optimisation : ajouter 3 liens internes → taux d’indexation 78%
- Recommandation :
- Ajouter des liens dans les articles connexes
② Optimisation de la profondeur de navigation (33% des cas)
- Impact du nombre de clics :
- Pages nécessitant plus de 4 clics → fréquence de crawl -57%
- Solutions :
- Navigation en fil d’Ariane (accélère l’indexation de 42%)
③ Mise à jour du sitemap (26% des cas)
- Fréquence de mise à jour du sitemap :
- Non mis à jour depuis plus de 30 jours → nouvelles pages retardées de 2-3 semaines
- Bonnes pratiques :
- Soumettre une fois par semaine (réduction du risque d’omission de 15%)
Autres optimisations clés (résout 16% des cas)
① Gestion du budget de crawl (39% des cas)
- Problème des grands sites : les sites >50 000 pages ne voient que 35% de leurs pages explorées régulièrement
- Méthode d’optimisation :
- Bloquer les pages de faible valeur (augmentation du crawl du contenu important 2,1x)
② Réduction de la période de sandbox (31% des cas)
- Temps d’attente pour les nouveaux sites : plus lent de 4,8 jours par rapport aux sites anciens
- Méthode d’accélération :
- Obtenir 3 backlinks de qualité (réduction de la sandbox de 40%)
③ Levée des sanctions manuelles (15% des cas)
- Période de récupération : 16-45 jours
- Causes principales :
- Liens spam (68%)
- Contenu déguisé (22%)
- Solutions :
- Utiliser le Google Disavow Tool pour nettoyer les liens spam
Effets attendus
| Mesure d’optimisation | Durée d’exécution | Amélioration du taux d’indexation |
|---|---|---|
| Correction du robots.txt | 1 heure | +27% |
| Optimisation de la vitesse de chargement | 3-7 jours | +62% |
| Ajout de liens internes | 2 heures | +69% |
| Mise à jour du sitemap | 1 fois par semaine | +15% |


